
목차
일본 애니메이션의 스폰서 영상 탐지하기
주제 및 배경 설명
/*
이 문서를 적는 이유 소개
민감한 주제일 수 있으나 공유나 이런 문제에 대해서는 조금 기준을 완화 부탁.
당연히 정식 루트가 아님. 솔직히 본인도 이러한 문서를 공개하는 일이 껄끄러웁긴 하지만
실용적인 수준이 아닌 호기심을 충족하는 측면에서 이해를 부탁드림.
*/
오래간만에 문서 올립니다. 이번에도 덕력과 잉여력을 뽐내는  문서입니다만, 호기심이 생기면 풀릴 때까지 해 봐야 되는 것 아니겠습니까. 이번에 설명드리는 문서는 일본 애니메이션(혹은 드라마 영상) 비디오에서 '스폰서 소개'가 들어간 영상인지, 아닌지를 판단하는 것입니다.
문서입니다만, 호기심이 생기면 풀릴 때까지 해 봐야 되는 것 아니겠습니까. 이번에 설명드리는 문서는 일본 애니메이션(혹은 드라마 영상) 비디오에서 '스폰서 소개'가 들어간 영상인지, 아닌지를 판단하는 것입니다.
일단 문서를 시작하기 전에 확실히 해 두고 가야 할 문제가 있습니다. 제가 처음으로 클리앙에 올린 파이썬 문서인 '네이버 웹툰 저장하기(1부, 2부, 3부, 내부위키)' 문서는 제가 처음으로 올린 문서이자 가장 호응이 많았던 문서이기도 합니다. 주제가 확실히 심플한데다 흥미를 주는 요소가 있다 보니 많은 분들이 따라하셨던 것 같습니다. 그런데 이번 문서는 어쩌면 '웹툰 저장하기' 보다 조금 더 논란의 소지가 있을 수도 있다고 생각합니다. 그렇기에 확실히 말씀을 드리고 시작하겠습니다.
- 이 문서는 개인이 사소한 문제를 발견하고 해결하는 과정을 서술한 개인적인 문서입니다. 절대 P2P 등을 이용해 저작권이 있는 매체에 대한 불법적인 공유를 권장하기 위해 작성된 것이 아닙니다.
- 문서는 오직 기술적인 사항만을 다룹니다. 영상의 취득법 및 기타 관련 사항은 다루지 않습니다. 또한 이와 관련된 질문도 받지 않겠습니다.
동기
/* 다시 강조. 본 문서의 내용은 저작권 따위는 엿바꿔먹겠냐는 뜻으로 비칠 수 있는데, 그런 행위를 권장하자고 글 쓰는 게 아님을 명시 중립적 */ 인터넷에 떠도는 일본 애니메이션 영상 파일들을 보면 약 10초의 스폰서 소개가 들어간 버전과 그렇지 않은 버전 두가지가 있습니다. 소개가 들어간 것을 '스폰서 버전', 그렇지 않은 것을 '논스폰서 버전'이라고 부르지요. 그 한 작품에서도 어떤 에피소드는 스폰서 버전, 다른 에피소드는 논스폰서 버전으로 릴리즈됩니다. 어떤 영상이 스폰서인지, 논스폰서인지는 따로 표기되어 있지 않기 때문에 판단하기 위해서는 직접 열어보는 수 밖에 없습니다. 개인적으로 이걸 알아채는 프로그램이나, 그러한 프로젝트가 있으면 재밌겠다고 생각해 본 문서를 작성해 보았습니다.
용어 설명
/* 여기서는 문서에서 쓰는 기본적인 용어를 설명해주어야 함 */ 초고속 인터넷이 보급된 이래로 영화, 애니메이션, 음악 같은 콘텐츠는 꾸준히 공유 대상이 되어 왔습니다. 저작권과 맞물린 문제이기는 합니다만, 엄연히 있는 사실이기도 합니다. 오랜 기간 활동해온 역사가 있는 만큼 이 '어둠의 루트' 또한 나름의 체계를 갖추고 있습니다.
릴
'릴'이란 말은 릴리즈(release)의 약자입니다. 영상을 배포하려면 우선 영상을 획득하고, 가공하는 작업이 필요합니다. 이것을 전문적으로 하는 비공개적인 단체가 있는데 이를 일컬어 '릴그룹'이라고 합니다. 보통 릴그룹은 프로그램을 녹화하여, 방송 중 삽입되는 광고 등은 편집하여 적절하게 압축한 다음 인터넷을 통해 배포합니다. 당연히 녹화는 디지털 방식으로 되며, 보통 1280×720 해상도에 x264 코덱을 사용합니다. 상당히 고된 작업일텐데 어찌하여 끊이지 않고 줄기차게 이어져 오는지는 정말 의문입니다.
스폰서
 앞서 릴된 파일은 '스폰서 버전'과 '논스폰서 버전'으로 나뉜다고 설명드렸습니다. 스폰서 버전은 위 그림과 같은 영상이 약 10초간 재생되는 것을 말합니다. 10초간 음악과 나레이션이 삽입1)됩니다. 이 때 그림과 같이 자막이 같이 삽입됩니다. 흰색에 검정 외곽선을 얇게 두르고 있는 형태가 거의 대부분입니다.
앞서 릴된 파일은 '스폰서 버전'과 '논스폰서 버전'으로 나뉜다고 설명드렸습니다. 스폰서 버전은 위 그림과 같은 영상이 약 10초간 재생되는 것을 말합니다. 10초간 음악과 나레이션이 삽입1)됩니다. 이 때 그림과 같이 자막이 같이 삽입됩니다. 흰색에 검정 외곽선을 얇게 두르고 있는 형태가 거의 대부분입니다.
일본 애니메이션의 경우, 연출상 항상 그런 것만은 아니지만, 일반적으로 특정 시간에 특정 파트가 재생되는 규칙이 있습니다.
- 오프닝 테마
재생시간은 일반적으로 1분 30초입니다. 주제곡도 이 시간에 맞춰 적절히 편집됩니다. - 스폰서 영상
문제의 스폰서 영상입니다. 보통 10초간 재생됩니다. 릴그룹에서 이를 의도적으로 편집해버리는 경우도 있습니다. 이렇게 처리하면 논스폰서 영상이 됩니다. - CF 방송
스폰서 영상이 나온 후에는 원래 CF가 방영됩니다. 릴된 영상에서는 대개 이 부분은 편집되어 보이지 않습니다만, 때때로 실수로 편집되지 않은 채 릴되는 경우도 있습니다. - A 파트
CF 이후 해당 에피소드의 A 파트가 방영됩니다. - 아이캐치
A 파트가 끝나면 주의를 환기시키는 짤막한 클립이 나옵니다. - 중간 CF
한국과는 달리 중간 CF가 있습니다. - 아이캐치
CF 이후 아이캐치가 다시 나옵니다. 이전 아이캐치와 같을 수도 있고 다를 수도 있습니다. - B 파트
한 에피소드의 나머지 분량이 방영됩니다. - 엔딩 영상
엔딩 주제가와 영상이 1분 30초 가량 방영됩니다. - 차회예고
엔딩 영상 이후에 차회 예고가 나옵니다. - 스폰서 영상
차회 예고 후 다시 스폰서 영상이 10초 재생됩니다.
보통 애니메이션 1에피소드는 CF를 제외하면 러닝타임이 24분입니다. 그런데 논스폰서 영상은 방송 앞뒤로 나오는 총 2회의 스폰서 영상 공지가 삭제되므로 20초의 재생시간이 줄어듭니다. 그러므로 보통 논스폰서 영상은 23분 40초 남짓, 그리고 스폰서 영상은 24분 00초 남짓에서 결정됩니다. 그러나 언제나 자로 딱 잰듯 되지는 않습니다. 일단 모든 방송이 24분은 아니며, 연출을 위해 앞서 언급한 순서는 언제든지 무시될 수 있습니다. 예를 들어 스폰서 10초 영상이 방송 시작부터 나올 수도 있다는 것이죠. 그리고 릴그룹이 편집을 하다 실수를 하는 경우도 간간히 있습니다. 그러므로 제가 나열한 순서와 규칙은 언제든지 변화할 수 있는 아주 느슨한 것입니다.
연구 과정들
스폰서 영상의 관찰
스폰서 영상이 어딘가에 나온다는 사실을 알고 있습니다. 그러나 어떤 장면이 스폰서 영상인지 아닌지는 어떻게 판별할까요? 기본적인 문제입니다. 그러면 앞서 소개한 스폰서 예시 그림을 다시 보면서 분석을 해 보도록 하겠습니다.
- 스폰서 영상에 삽입되는 폰트는 거의 흰색입니다.
- 자막은 거의 항상 '提供(제공)'이라는 문자가 첫 행에 나옵니다.
- 이 자막의 위치도 수평적으로는 거의 고정되어 있으며, 수직으로도 화면의 절반 아래로는 나오는 일이 없습니다. 즉 아래 그림과 같이 투명하게 붉은 영역에서만 제공이라는 글자가 나옵니다.

- 이 스폰서 화면은 거의 항상 흰색 글자입니다. 이유는 정확히 알 수 없으나, 법률로 규정된 것이 아닌가 생각합니다.
- 그리고 스폰서 영상의 배경은 정지해 있을 수도 있고, 움직일 수도 있지만, 시각적으로 글씨의 가독성을 크게 떨어뜨리지는 않습니다.
- 릴되는 영상은 보통 약 24fps입니다. 그러므로 스폰서 영상은 파일 내 전반 스폰서만 약 240, 후반 스폰서까지 포함하면 약 480 프레임을 차지하는 셈입니다.
몇몇 시도들
첫번째 시도
일단 몇몇 파일에서 스폰서 영상만을 추출해 스폰서 영상인지를 확인하는 과정을 만들어 보고자 합니다. 즉 어떤 한 프레임을 주었을 때 그것이 스폰서 영상에서 추출한 한 프레임인지, 아닌지는 판단할 수 있도록 작업하는 것입니다.
스크린 샷 찍기
작업을 쉽고 간단하게 하기 위해 미리 스폰서 영상의 스크린샷을 준비합니다. 윈도우건 리눅스건 왠만한 재생기는 다 스크린샷을 찍는 기능이 있으니 어려운 작업은 아닙니다.
스크린 샷 이미지 편집
스크린샷을 그대로 활용하기는 현란한 색상이 너무 많아 부담렇습니다. 아무래도 이미지를 편집할 수 있는 툴이 필요합니다. 포토샵? 물론 강력한 툴입니다만, 프로그램에서 사용하기는 조금 어렵지요 게다가 상용 툴이잖아요  프로그래밍? 처음부터 프로그램을 짜는 것은 좀 아닌 것 같군요. 이럴 때는 imagemagick 이라는 오픈소스 프로그램의 힘을 빌리는 것이 좋겠네요. 윈도우, 리눅스, 맥 등을 안 가리고 쓸 수 있고 리눅스면 왠만한 배포판에서는 거의 설치되어 있거나 매우 간단히 설치됩니다.
프로그래밍? 처음부터 프로그램을 짜는 것은 좀 아닌 것 같군요. 이럴 때는 imagemagick 이라는 오픈소스 프로그램의 힘을 빌리는 것이 좋겠네요. 윈도우, 리눅스, 맥 등을 안 가리고 쓸 수 있고 리눅스면 왠만한 배포판에서는 거의 설치되어 있거나 매우 간단히 설치됩니다.
Thresholding
Imagemagick은 'convert'라는 커맨드 라인 툴을 제공합니다. 이 프로그램을 조금만 사용할 줄 알면 간단한 사진 편집은 손쉽게 할 수 있죠. 나름 굉장한 녀석인데 커맨드 라인 툴이라 그다지 사랑받지 못합니다만, 이럴 때는 더할 나위 없이 훌륭합니다. 우리는 이미지에서 글자로 추축되는 영역만 골라내는 작업이 필요합니다. 앞서 살펴본 스폰서 영상의 특징 상 이 작업은 너무나 간단합니다. threshold를 이용하는 것이죠. threshold는 다음과 같이 이용하면 됩니다.
$ convert -threshold 50% input.png
'threshold가 뭐야?' 라고 궁금해 하실 분들이 있을 지 모르겠습니다. Threshold란 사전적 의미 그대로는 '한계점, 기준치, 문턱'입니다. “어떤 값이 기준치를 넘겼다, 넘기지 못했다”라고 말할 때의 그 '기준치'를 말합니다. (이미지 출처: http://www.svi.nl/SeedAndThreshold)

convert 는 threshold를 이렇게 처리합니다.
- threshold를 넘는 픽셀은 100%로 처리한다.
- threshold를 넘지 못하면 0으로 처리한다.
convert는 입력된 그림파일의 픽셀을 일일이 검사합니다. 보통 픽셀은 보통 0~255의 단계값을 가집니다. 0이면 완전히 검은색, 255면 완전히 밝은 흰색입니다. 위 convert 명령의 예제는 그림의 펙셀에서 밝기 값이 50% 이상인 값은 100% 값을 가지고, 그렇지 못하면 0으로 만들라는 뜻입니다. 보다 알기 쉽게 예를 들어 보도록 하지요 5개의 픽셀이 있습니다. 각 픽셀은 다음과 같은 밝기를 가집니다.
160, 120, 48, 140, 230
가장 높은 값인 255의 50%는 127.5입니다.
- 160 > 127.5 –> 255
- 120 < 127.5 –> 0
- 48 < 127.5 –> 0
- 140 > 127.5 –> 255
- 230 > 127.5 –> 255
그러므로 결과는
255, 0, 0, 255, 255
모든 픽셀 값이 255, 아니면 0으로 현격하게 갈립니다. 그러면 직접 convert를 그림 파일에 대해 직접 실행한 결과를 보도록 하지요. 대략 97% 정도를 threshold 값으로 주었을 때의 결과입니다.
 잡다한 영상은 싹 날아가고 흰색의 글자만 두드러지게 남은 것을 알 수 있습니다. 스폰서 영상에 나오는 글자가 가장 높은 밝기인 흰색으로 되어 있고, 글자와 영상의 대비가 크기 때문에 이렇게 좋은 결과가 나오는 것입니다.
잡다한 영상은 싹 날아가고 흰색의 글자만 두드러지게 남은 것을 알 수 있습니다. 스폰서 영상에 나오는 글자가 가장 높은 밝기인 흰색으로 되어 있고, 글자와 영상의 대비가 크기 때문에 이렇게 좋은 결과가 나오는 것입니다.
Tesseract
threshold 처리를 하면 비교적 좋은 결과가 나옵니다. 사실 영상 처리의 다양한 알고리즘을 잘 이해하신 분이라면, 뭐 이미 갖가지 훌륭한 방법을 통해 좋은 결과를 도출하실 수 있으리라 믿습니다. 그러나 저는 그 정도는 아닌데다, 일단 처음이니 가장 사람과 유사하고, 직관적이며, 단순한 방법이 더욱 효과적이라 판단했습니다. OCR (Optical Character Recognition) 말이죠. 오픈 소스에서도 OCR관련 소프트웨어가 분명히 있으리라 생각해 조금 조사해 보았습니다. tesseract라는 프로젝트가 있었더군요. tesseract는 아마 왠만한 리눅스 배포판에서는 패키지로 제공될 것입니다. 설치 과정은 생략하겠습니다. 단 설치하실 때 “Japanese language data set”은 잊지 말고 같이 설치하세요. '提供(제공)'이라는 한자어를 처리할 것이니까요. tesseract를 설치하면 바로 결과를 테스트해 볼 수 있습니다.
$ tessearct <입력파일> <출력파일> -l jpn $ tesseract test01_mono.png test -l jpn # 원본이미지가 아닌, threshold 처리를 한 파일을 사용하세요. 출력파일에는 자동으로 .txt 확장자가 붙습니다.
이렇게 하면 test_01_mono.txt 파일이 생성됩니다. tesseract의 결과는 이렇습니다2).
提 供 KADOKAVVA
'KADOKAWA'가 아니라 'KADOKAVVA'지만 뭐 상관없습니다. 提供이라는 한자 사이에 공백이 하나 삽입되네요. 아무튼 인식이 잘 됩니다.
첫번째 시도 방법
구현 과정
위 재료를 잘 버무리면 뭐 그런대로 괜찮은 결과가 나오리라 생각했습니다. 첫번째는 거의 쉘 스크립트에 가깝습니다만, 파이썬으로 만들도록 하지요. 쉘 스크립트를 만들면 윈도우 사용자들이 아마 불편하실거에요  대신 파이썬이라 할지라도 마치 쉘 스크립트와 유사하게 커맨드 라인을 실행하는 방식으로 1차 구현을 할 생각입니다. 라이브러리를 사용하는 게 아니라요.
대신 파이썬이라 할지라도 마치 쉘 스크립트와 유사하게 커맨드 라인을 실행하는 방식으로 1차 구현을 할 생각입니다. 라이브러리를 사용하는 게 아니라요.
파이썬에서 외부 명령을 실행하는 가장 간단한 방법 중 하나는 os.system()을 이용하는 것입니다. 이것을 이용해 원본 동영상에서 일정 간격으로 한 프레임을 얻어내고, 그 한 프레임이 스폰서 영상인지 아닌지를 'convert' 프로그램과 'tasseract' 프로그램이 판단하는 것입니다. 정말 무식한 방법입니다만, 현재로서는 스마트한 방법 따위는 머릿속에 떠오르지 않네요. 그리고 정말 이 방법이 동영상에 대해서도 통하는지 의문이구요.
구현 결과
파이썬 코드는 detect_sponsor.py 입니다. 실행하는 디렉토리에 'img'라는 하위 디렉토리를 미리 만들어두세요.
- detect_sponsor.py
#!/usr/bin/python # -*- coding: utf-8 -*- import os import sys def parse_argv(argv): if len(argv) != 2: print "Usage: detect_sponsor.py <input_file>" sys.exit(1) return argv[1] def detect_sponsor(file_name): # 영상 파일의 1분 20초부터 5분 00초까지 # 매초 3장의 스크린샷을 추출한다. cmd = 'ffmpeg -ss 00:01:20 -t 00:03:40 -i \"%s\" -f image2 -r 0.33 -vcodec png img/image_%%03d.png' % file_name os.system(cmd) # 추출된 파일의 threshold를 대략 95% 정도 주어서 이진화시킨다. for file in os.listdir('./img'): file_path = './img/' + file conv_cmd = 'convert -threshold 95%% %s ./mono.png' % file_path os.system(conv_cmd) # 이진화된 영상에 tasseract 일본어를 적용시킨다. ocr_cmd = 'tesseract ./mono.png result -l jpn' os.system(ocr_cmd) with open('result.txt', 'r') as f: first_line = f.readline() if first_line.strip() == '提 供': print file_path, 'has sponsor text!' break for file in os.listdir('./img'): file_path = './img/' + file os.remove(file_path) def main(argv = None): file_name = parse_argv(argv) detect_sponsor(file_name) if __name__ == '__main__': sys.exit(main(sys.argv))
프로그램은 ffmpeg을 이용해 1분 20초에서 5분까지의 영상을 매초 3장의 스크린샷을 뽑아냅니다.
- ss 시작 시간입니다.
- t 재생 시간입니다. 1분 20초 + 3분 40초 = 5분 00초입니다.
- r fps를 의미합니다. 0.33이므로 초당 3장을 재생합니다.
그리고 모든 스크린샷에 대해 convert가 threshold를 먹이고, tesseract가 글자를 판별합니다. 일단 이 방법은 끔찍하게 느립니다. 아래 코드는 파이썬의 multiprocessing 라이브러리를 이용해 간단히 멀티코어 처리로 변환시켜 본 것입니다. multiprocess 라이브러리를 이용해 멀티코어 처리도 해 보았습니다만, 멀티코어라고 해서 엄청난 성능 향상이 있는 것도 아닙니다. 일단 tessearct라는 라이브러리의 인식 결과가 큰 영향을 미치고 있네요.
- detect_sponsor_mp.py
#!/usr/bin/python # -*- coding: utf-8 -*- import multiprocessing as mp import os import time import sys def parse_argv(argv): if len(argv) != 2: print "Usage: detect_sponsor.py <input_file>" sys.exit(1) return argv[1] def ts2sec(ts): h = int(ts[0:2]) * 3600 m = int(ts[3:5]) * 60 s = int(ts[6:8]) return h + m + s def sec2ts(sec): s = sec % 60 sec /= 60 m = sec % 60 sec /= 60 h = sec return '%02d:%02d:%02d' % (h, m, s) def make_time_sequence(file_name, start_time, end_time, timestep): st_sec = ts2sec(start_time) ed_sec = ts2sec(end_time) sequence = [(file_name, sec2ts(x)) for x in range(st_sec, ed_sec, timestep)] return sequence def detect_sponsor(file_name): sequence = make_time_sequence(file_name, "00:01:20", "00:05:00", 3) pool = mp.Pool(mp.cpu_count() * 2) results = pool.map(core_func, sequence, len(sequence)/4) pool.terminate() pool.join() #results = [core_func(x) for x in sequence] for r in results: if r[1] == True: print "found sponsor text in", r[0] return print 'no sponsor text found' def core_func(seq): # 영상 파일의 1분 20초부터 5분 00초까지 # 매 3초당 스크린샷을 추출한다. file = seq[0] ts = seq[1] path = './img/image_%s.png' % ts cmd = 'ffmpeg -ss %s -i \"%s\" -f image2 -vframes 1 -vcodec png %s' % (ts, file, path) os.system(cmd) # 추출된 파일의 threshold를 대략 95% 정도 주어서 이진화시킨다. thresh_file = './mono_%s.png' % ts conv_cmd = 'convert -threshold 95%% %s %s' % (path, thresh_file) os.system(conv_cmd) # 이진화된 영상에 tasseract 일본어를 적용시킨다. result_file = './result_%s' % ts ocr_cmd = 'tesseract %s %s -l jpn' % (thresh_file, result_file) os.system(ocr_cmd) ret = False with open(result_file+'.txt', 'r') as f: first_line = f.readline() if first_line.strip() == '提 供': print result_file, 'has sponsor text!' ret = True os.remove(thresh_file) os.remove(result_file+'.txt') return (ts, ret) def main(argv = None): file_name = parse_argv(argv) detect_sponsor(file_name) if __name__ == '__main__': sys.exit(main(sys.argv))
결과 분석
tesseract라는 '문자 인식' 과정에 전적으로 의존합니다. convert -threshold의 결과가 그다지 좋지 않았다면 tesseract의 인식률은 많이 떨어져버립니다.
일례로 아래와 같은 스폰서 영상은 비교적 인식이 잘 됩니다. 95%로 threshold한 결과를 덧붙였습니다.


반면 아래와 같은 스폰서 영상은 인식에 실패합니다. 마찬가지로 95%로 threshold한 결과를 덧붙였습니다.


왜 이럴까요? 혹시 아래처럼 '제공' 부분만 잘라내서 인식하면 안될까요?
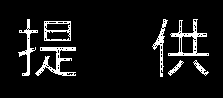 의외로 잘 되지 않는군요. Threshold를 92%까지 낮춘 후 비슷하게 crop을 해 보았습니다.
아래는 그림은 92% threshold와 crop한 결과입니다.
의외로 잘 되지 않는군요. Threshold를 92%까지 낮춘 후 비슷하게 crop을 해 보았습니다.
아래는 그림은 92% threshold와 crop한 결과입니다.

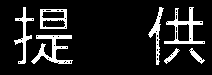
이렇게 결과를 분석했습니다. 인식이 잘 되는 이미지는 배경 이미지가 대부분 threshold를 넘지 않습니다. 이렇게 되면 배경 이미지는 모두 검게 나오고 자막에 쓰인 흰색만 이미지로 나옵니다. tesseract는 이러한 이미지를 잘 인식해 글자로 만듭니다.
그러나 배경 이미지가 비교적 밝은 이미지라면 threshold값을 넘는 픽셀이 많이 발생합니다. 이렇게 threshold가 넘는 값이 많아지면 tesseract의 문자 인식에 상당한 영향을 끼칩니다.

한편 threshold 값 또한 한자의 인식 결과에 큰 영향을 주는 요소로 작용하는 것으로 보입니다. 일반적으로 한자는 영어에 비해 그 인식률이 낮은 것으로 알려져 있습니다. 글자 수도 워낙 많은 데다 모양이 복잡하기 때문이지요. '제공'이라는 글자 주변을 크롭해서 주변에 노이즈가 될 만한 상황을 제거했음에도 불구하고 95% threshold 크롭 버전은 tessesract가 인식하지 못했습니다. 반면 단 3%밖에 차이가 나지 않은 92% threshold 크롭 버전에서는 글자가 인식됩니다. 둘의 차이는 육안으로는 그렇게 도드라지게 보이지 않습니다. 자세히 들여다 보아야 95%쪽 글자 내부에는 듬성듬성 구멍이 많이 뚫려 있다는 것을 알아챌 수 있습니다.
다음을 위한 대책
ffmpeg, convert, tasseract, 이렇게 세 가지 커맨드라인 툳을 이용하다보니 각 단계에서 파일 입출력이 발생합니다. 그러다보니 프로그램의 실행속도가 많이 느려질 수 밖에 없겠지요. 이 부분만 해결해도 상당히 속도를 해결할 수 있으리라 생각합니다.
ffmpeg이 하던 동영상 읽기, convert가 하는 한 프레임의 threshold 처리는 opencv를 이용하고, tesseract 또한 커맨드 라인이 아닌, 라이브러리가 제공하는 API를 이용한다면 어떨까요? 이것만으로도 속도는 많이 개선될 수 있을 것 같습니다.
물론 '파이썬'이라는 언어 자체가 가진 느림이 있습니다만, 그건 그냥 느림의 미학  으로 남겨두겠습니다. 아직은 “파이썬이 느려서 프로그램이 느린 거야!”라고 주장할 단계가 아닌 듯합니다.
으로 남겨두겠습니다. 아직은 “파이썬이 느려서 프로그램이 느린 거야!”라고 주장할 단계가 아닌 듯합니다.
또한 제공이라는 글자는 거의 화면의 12시 방향에 고정되어 나오므로 tasseract가 입력 영상의 모두를 처리해서 인지할 필요 없이, 거의 '제공'이라는 단어가 나오는 부분만 잘라내어 입력을 할 수 있을 것입니다. 그렇게 하면 tessertact가 인식하는 속도도 비약적으로 향상되겠지요. 한편 이런 생각을 해 볼 수도 있습니다. 애초에 “제공”이라는 글자 자체를 인식해서 텍스트로 결과를 정확히 얻어 내야만 되는 것일까? 하는 문제이죠. 사실 사람도 그렇습니다. 저것이 스폰서 화면이다, 아니다를 판별할 때 한 글자 한 글자를 꼼꼼하게 읽어서 한 글자도 틀리지 않게 인식한 다음 판단하나요? 그렇진 않지요. 대충 어떤 화면에 흰색 글자가 고정되어 나타나고, '고노 방구미와~ 고란노 스폰사데~' 같은 음성이 나오며, 흰색 글자는 평소에 보아 오던 대로 대략 제공이나 스폰서의 로고들이 나온다는 사실만 슥 보고 바는 겁니다. 예컨데 누가 일부러 'KADOKAWA'라는 글자를 'KADOKAVVA'라고 글자를 적당히 틀리게 썼다고 생각해 보지요. 물론 그걸 정확히 캐치해내는 시청자도 있겠지만, 대개 많은 이는 그걸 무시하거나 인지하지 못한 채 넘어갈 겁니다. 사악하게(?) VV의 자간을 더욱 그럴듯하게 조절하면 모두를 깜빡 속일 수도 있지만, 오히려 그 경우라면 KADOKAWA든 KAOKAVVA든 어쨌든 사람들은 평소 접하던 오리지널인 KADOKAWA라고 생각할테니 홍보 효과에는 별 차이가 없을 거란 말입니다.
영상이 아닌 '음성까지 동원하여 스폰서 화면을 캐치해보면?'이란 아이디어는 생각해 본 적이 있었으나 제가 음성 인식 쪽에는 영상 처리보다도 아는 것이 없는데다, …. 스폰서 영상 하나 탐지하자고 별 난리를 치는 꼴이 되는 것 같네요. 그냥 영상 처리를 이용해 인식하는 것으로 만족하겠습니다. 그리고 위 문단에서 '평소 보아오던 대로'라는 부분은 특별히 강조한 이유가 있습니다. 저것을 활용하면 굳이 tesseract라는 문자 인식 기능을 붙이지 않아도 될 것 같은 생각이 드는데요, 아직은 그 쪽으로는 생각하지 않고, 일단 tesseract가 깔끔하게 문자를 인식해 낼 수 있도록 처리하는 쪽으로 방향을 잡았으면 합니다.
결론
갑자기 결론이 뜬금없이 나와 이상하긴 합니다만, 저는 '이러이러하게 하면 성능은 개선될 거야'라고 제안하는 수준에서 이 문서와 작업을 마치고 싶습니다. 사실 문서의 내용이야 간단하게 파이썬, 프로그래밍에 관심 있으신 분들이 한 번 참고할 만한 내용이라 생각하므로 공개해서 서로 나눔을 해도 크게 문제가 없다고 생각하지만, 그래도 이 문서를 계속 발전시켜야 할 지에 대해서는 좀 의문이 들기 때문입니다.
여기까진, 정말 여기까지는, 호기심의 일환으로 진행해 보았습니다. 그러나 아무리 제가 문서에서 공유를 조장하려는 의도가 아니라고 못을 박긴 했어도, 이유야 어쨌든 음성적인 콘텐츠를 대상으로 작업을 한 것이 사실입니다. 이러한 사실을 눈감은 채 그렇게까지 공을 들여 작업하고 싶은 생각은 없습니다. 우연히 들게 된 개인적인 호기심을 충족시키는 면에서는 이 정도로도 충분히 성공적이라고 생각하니까, 이 정도로 마무리짓는 것이 옳지 않을까 합니다. 만일 합법적인 콘텐츠 분야에서 문서가 서술한 어떠한 부분이 필요하다는 요구가 있다면야 저는 주저없이 이 문서 작업을 계속할 의도가 있습니다. 그러나 그렇지 않는 한은 잘 모르겠습니다.
/*
두번째 시도
두번째 시도 방법
구현 과정
구현 결과
결론
스폰서 영상이란 것 자체가 일본방송을 립해서 올리는 그 영상에만 해당하는 카테고리라서 불법공유를 양성화하자는 것도 아니고, 단지 개인적인 호기심이었으니 여기까지 한 것으로 만족한다. 만일 합법적인 분야에서 이러한 방법이 유용하고 가치 있는 일이라면 주저않고 성능을 개선할 의도가 있다.
프로그램을 더 개선할 방향: 더 빠른 언어로 구현/휴리스틱 활용/스폰서 글자가 나오는 위치의 조정 */