
목차
네이버 웹툰 저장하기
파이썬(Python)을 이용한 실습의 일환으로 네이버 웹툰을 PC에 자동 저장하는 스크립트를 만들어볼까 합니다. 파이썬을 간단하게 공부해보고 싶으신 분들을 대상으로 문서를 작성합니다. 윈도우 환경에 파이썬 2.7을 기반으로 하여 프로그램을 설명하도록 하겠습니다.
주의 사항!
본 문서는 python을 파이썬을 학습에 조금이나마 도움을 주기 위한 목적으로만 작성되었습니다. 수집한 각 웹툰은 저작권이 허용하는 범위 안에서만 이용하십시오. 웹툰의 감상은 웹사이트를 통해 하시기 바랍니다. 이 문서를 보시는 분들의 상식을 믿겠습니다.
프로그램의 동작 방식 설명
웹페이지의 주소 분석하기
웹페이지 주소 들어가보기
원하는 작품의 원하는 회차를 저장하기 위해서는 먼저 주소 체계에 대한 지식이 있어야 합니다. 그러므로 우선 본 장에서는 웹페이지의 주소에 대한 설명을 하고자 합니다. 설명이 장황해질 수 있으므로 최대한 간결하게 설명하고 넘어가도록 하겠습니다.
우선 웹툰 홈페이지에서 원하는 웹툰을 선택해야겠죠. 우선 웹브라우저를 열어 웹툰을 하나 선택하세요. 그럼 가장 먼저 웹브라우저의 주소를 자세히 살펴보도록 할까요? 아마 주소는 이렇게 시작할 겁니다.
http://comic.naver.com/webtoon/detail.nhn?titleId= ...
주소의 각 부분에 대한 설명
이 주소를 좀 더 자세히 분석하면 다음과 같이 나눌 수 있습니다.
- http:// 부분: http
- comic.naver.com 부분: 도메인 네임
- /webtoon/detail.nhn 부분: 문서 경로
- ?titleId=… 부분: GET 변수/값 목록
그럼 각 부분에 대한 간단한 설명하도록 하지요.
http
http:// 는 웹브라우저를 통해 http(Hyper Text Transfer Protocol)를 사용하겠다는 의미입니다. 웹페이지 주소를 나열할 때 주로 사용되므로 이제는 이것이 매우 낯선 단어는 아니라고 생각합니다. http와 같은 '프로토콜'에 대한 자세한 설명은 생략하겠습니다. 웹페이지를 열 때 필요한 부분이라고 생각하시면 됩니다.
도메인 네임
comic.naver.com 또한 별 설명이 필요없을 겁니다. 우리는 naver.com에 접속하고 싶다는 의미이죠.
문서 경로
/webtoon/detail.nhn은 클라이언트가 서버에게 무엇을 원하는지를 설명하는 문장입니다. 이를 사람과의 대화로 비유하자면 이렇습니다.
- PC(클라이언트): 서버야, 너 /webtoon 디렉토리에서 detail.nhn 이라는 파일 좀 보내줘
- 서버: 어 알았어, 기다려봐. (파일을 찾아 있다면) 응 여기 detail.nhn이라는 파일이 있네 전송한다. (파일이 없다면)응? 네가 말한 파일은 내가 가지고 있지 않아!
GET 변수/값 목록
?titleId=… 부분은 쉽게 말해 서버의 detail.nhn이 전달하는 내용은 사용자의 요청에 따라 능동적으로 변할 수 있기 때문에 필요한 부분입니다. 여러분들은 각 웹툰을 감상할 때 만화의 내용은 다르지만 웹페이지의 디자인은 달라지지 않는 것을 보셨지요?
각 만화마다, 각 작품마다 웹페이지를 제작해야 한다면 웹페이지의 수가 너무 많아질 것입다. 이렇게 산만하게 수가 늘어나면 관리하기도 쉽지 않겠죠. 사실 '마음의 소리'와 '신과 함께' 만화의 내용은 각기 다르지겠만, 사실 웹페이지의 디자인 자체가 일일이 달라져야 할 필요는 없습니다. 그래서 문서를 제작할 때 변하는 부분과 변하지 않는 부분을 구분지어서 변하는 부분은 클라이언트가 요청할 때마다 동적으로 만들어서 보여주게 됩니다. 그러면 문서 하나로도 수백 수천개의 비슷한 부류의 문서를 커버할 수 있습니다.
서버는 공통적인 부분은 '템플릿'으로 저장합니다. 그리고 변동되는 부분에 대해서는 클라이언트가 필요할 때 만들어서 전송합니다. ?titleId=…는 바로 그 변동되는 부분이 어떻게 처리되어야 하는지 알려주는 스위치 같은 역할을 합니다. 이 문자열은 보통 물음표(?)로 시작하고 '&' 기호로 구분합니다.
그러므로 물음표 뒤의 문자열을 &로 나누게 되면, 대략
- titleId=XXXXXX
- no=XX (혹은 seq=XX)
이렇게 나눠질 것입니다. 그리고 각각 나눠진 문자열은 재차 등호(=)로 나눌 수 있습니다. 등호 좌측의 문자열은 '변수(variable)', 등호 우측의 문자열은 '값(value)'입니다.
웹브라우저에서 서로 다른 작품들/다른 회차에 접속해서 값이(간혹 변수가) 어떻게 바뀌는지 확인해보세요. 또 전혀 다른 웹페이지들에 접속해서 물음표 뒤에 나오는 변수와 값들을 살펴보세요. 이렇게 웹페이지 주소에 클라이언트가 요청에 필요한 요소들을 같이 보내는 것을 'GET' 방식이라고 말합니다.
결론
이 장의 결론입니다. 만화를 보기 위해서는 'GET' 방식으로 comic.naver.com에 접속하여 '/webtoon/detail.nhn'을 요청해야 합니다. 이 때 만화 작품 구분을 위해서는 'titleId'라는 변수와 작품마다 미리 정해진 값을, 만화 회차를 구분하기 위해서는 'no'(혹은 'seq')라는 변수와 회차 값을 적어서 보내야 합니다.
(사실 이렇게 동작하기까지 서버와 우리의 피씨, 즉 클라이언트 사이에 수많은 규약과 데이터가 밑바탕으로 깔려 있어야 합니다. 하지만 그런 자세한 사항을 일일이 알 필요는 없구요, 추상적으로 클라이언트가 '요청(request)'하면 서버는 그 요청에 따라 클라이언트에 '응답(response)'한다고 생각하시면 됩니다.)
웹페이지 소스 얻어오기
주소 체계에 대해 이해했으면 이제 실습을 하도록 하지요. 이 장에서 여러분들은 웹브라우저가 아닌 직접 작성한 프로그램을 통해 웹 페이지에 접속해보게 됩니다. 프로그램에 웹페이지 주소를 넣으면, 웹페이지의 HTML 코드를 얻는 거지요. 파이썬으로는 놀라울 정도로 간결하게 이 일을 할 수 있습니다.
인터프리터 열어서 맛보기
파이썬 인터프리터를 열어보세요. 그리고 다음과 같이 입력해보세요.
import urllib2 print urllib2.urlopen('http://www.google.com/').read()
구글의 소스 코드가 출력되어 나올 것입니다. 전 처음에 파이썬으로 단 2줄만에 웹페이지를 얻어올 수 있다는 사실에 충격 먹었었는데, 여러분들은 어떠시나요? 정말 간단하지요? 이제 http://www.google.com/ 대신에 웹툰 페이지를 입력해서 HTML 소스 코드가 나오는지 확인해보세요.
스크립트 작성하기
텍스트 편집기를 하나 열어서, 좀 더 정리된 상태의 스크립트로 편집해 보겠습니다. 텍스트 편집기는 아무 거나 써도 상관없지만, 그래도 쓰기 편리한 것이 좋습니다. 저는 Notepad++를 추천합니다. 기능도 훌륭하고, 무료입니다.
- gethtml.py
# -*- coding: cp949 -*- # 코드페이지를 지정합니다. 파이썬 스크립트 시작에 반드시 삽입해주세요. # 한글 윈도우면 'cp949', 리눅스면 보통 'utf-8'을 씁니다. import urllib2, sys # filename으로 contents를 기록합니다. def savefile(contents, filename): f = open(filename, 'w') f.write(contents) f.close() # url의 문서(HTML)를 읽어 리턴합니다. def gethtml(url): response = urllib2.urlopen(url) return response.read() # 메인함수 def main(argv): if len(argv) != 3: print 'Usage: gethtml.py <url> <savefile>' return 1 url = argv[1] savefile = argv[2] # url에 접근해서 파일 내용(HTML)을 얻어옴 html = gethtml(url) # 출력해서 확인 # print html # HTML을 파일로 저장 savefile(html, savefile) # 성공적으로 종료 return 0 # 파이썬은 스크립트 언어이므로 C/C++와 같이 main함수를 먼저 실행하지 않습니다. # 본 파일을 실행했을 때 main() 함수가 실행되기 위한 처리를 직접 해야 합니다. if __name__ == '__main__': sys.exit(main(sys.argv))
조금 내용을 덧붙였습니다. URL과 문서를 저장할 파일 이름을 인자로 넘기면, URL의 문서를 읽어들여 파일 이름으로 저장하는 간단한 프로그램입니다. 명령 프롬프트에서 아래와 같이 실행하면 됩니다.
python gethtml.py http://www.google.com google.html
HTML 분석하기
다시 한 번 강조합니다. 저는 이 문서를 그저 학습용으로만 제작하였을 뿐이고, 단순히 만화 이미지가 로컬 PC에 저장되는 것 자체만으로는 각 만화에 대한 저작권에 대한 침해가 아니라고 알고 있기에 본 문서를 공개하는 것입니다. 절대 저작권의 범위를 벗어나는 행동은 하지 마시기 바랍니다.
그럼 실제 웹툰 하나를 골라서 HTML을 분석해보도록 하겠습니다. 인기 연재중인 '마음의 소리'를 예로 들도록 하지요. 웹브라우저에 접속해서 주소를 살펴보면,'마음의 소리'의 titleId는 20853인 것을 알 수 있습니다. 그리고 weekday=tue 변수/값 쌍이 추가로 웹브라우저 주소란에 있는 것을 확인할 수 있습니다. 그러나 weekday 변수와 값은 삭제해도 문제가 없습니다.
이제 만화의 각 회차에 접속해 보세요. 그러면 주소에 새로운 변수 쌍인 no=XXX가 생긴 것이 보일 것입니다. 그러므로 네이버 웹툰은 titleId 변수로 각 작품을 구분하고 no 변수로 각 회차를 구분하고 있는 것입니다.
그럼 각 만화의 이미지 태그가 어디에 위치하는지를 알아야 하겠죠? 웹브라우저의 소스 보기 등으로 네이버 웹툰의 소스를 직접 분석해 보아야 합니다. Firefox의 '문서 검사' 기능 등을 통해 HTML 문서의 구조를 보다 손쉽게 파악할 수도 있습니다. 사실 웹툰 이미지에 대해 저작권 보호를 위해 보호 장치를 걸어 쉽사리 웹툰을 퍼갈 수 없도록 제한할 수도 있습니다. 그런 조치를 취할 수도 있지만 굳이 하지 않음을 참 다행으로 생각합니다.
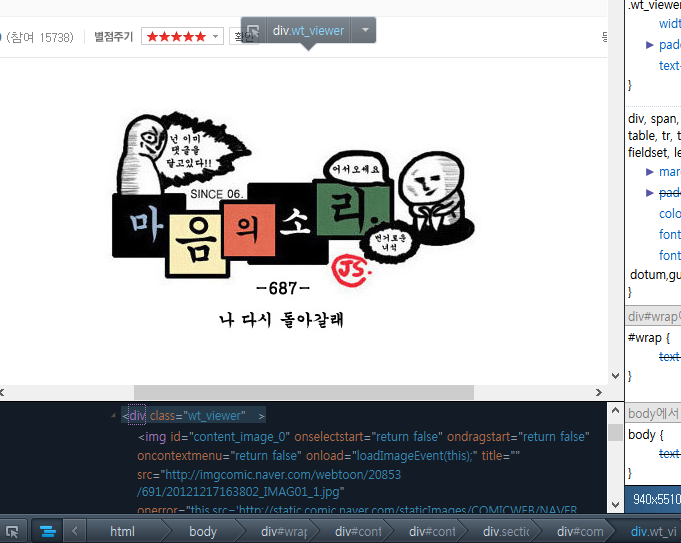
위 그림은 문서 검사를 통해 이미지 부분을 선택해 본 것입니다. 이미지는 <div class=“wt_viewer”> 라는 태그로 감싸져 있음을 파악했습니다. 그러면 이전 장에서 우리가 만든 프로그램을 통해 웹페이지의 HTML 소스를 다운로드 받아 보기로 하지요.
마음의 소리 691화의 페이지 소스를 다운로드 받는다고 하면,
python gethtml.py "http://comic.naver.com/webtoon/detail.nhn?titleId=20853&no=691" "마음의소리_691.html"
처럼 쓸 수 있겠네요. 문서를 열어 div class=“wt_viewer” 부분을 찾아 봅니다. div 아래에 img 태그가 있을 것입니다. 각 img 태그가 웹브라우저에 그림을 보여주는 역할을 합니다. img의 src 속성을 복사해서 웹브라우저의 주소창에 붙여넣기해 만화의 이미지가 맞는지 확인해 봅니다. 속성은 대략 http://imgcomic.naver.com/webtoon/20853/691/XXXXXXXXX.jpg 가 될 겁니다. 고맙게도 별 제재 없이 만화 이미지를 보여 주는 것을 확인할 수 있습니다. 만일, 이렇게 해서 만화 이미지가 보이지 않는다면 이 문서는 아무 쓸모가 없어집니다.
HTML에서 이미지만! 정규식을 사용하자
앞서 각 회차의 만화는 단순하 img 태그만을 이용해서 보여지는 것을 확인했습니다. 그러면 img 태그 중에서 만화를 보여주는 img 태그만 골라내서 src 부분의 주소를 추출해낼 수 있다면 각 이미지 파일에 대해 손쉽게 접근 가능하게 될 것입니다.
이렇게 하려면 원래 웹브라우저가 하는 것처럼 이 복잡한 HTML 태그를 모두 파싱(parsing)해야 합니다. 그러나 여기서는 정규식을 이용한 문자열 검색만으로도 원하는 결과를 손쉽게 얻어낼 수 있습니다.
정규식(regular expression)에 대해 본 문서에서 모든 것을 설명하기는 어렵습니다. 인터넷에 자료가 많으므로 쉽게 찾아볼 수 있습니다. 여기서는 사용된 구문에 한해 설명을 하도록 하겠습니다. 결론적으로 img의 src 속성을 추출하기 위한 정규식 구문은
<img.+?src="(http://imgcomic\.naver\.com/webtoon/[0-9]+/[0-9]+/(.+?\.(jpg|png|gif)))".*?>
입니다. 처음 보시는 분은 마치 암호와 같아 보일 것입니다. 천천히 설명하도록 하겠습니다.
- <img 는 당연히 문서에서 'img' 태그가 시작되는 부분을 뜻합니다.
- .+? 세 문자는 다음과 같은 의미를 지닙니다.
- img 다음의 점(.)은 '아무 문자'를 의미합니다. 숫자, 영문자, 한글, 공백 어떤 것이든 딱 '한 글자'를 의미합니다.
- 점 다음의 더하기 기호(+)는 '1회 이상의 반복'을 의미합니다. 그리하여 .+는 어떤 글자든 한 번 이상 반복되는 것을 의미합니다.
- 더하기 기호 다음의 물음표(?)는 이러한 문자 매칭이 최소한만으로 이뤄지도록 조정하기 위함입니다.
앞서 .+가 어떤 문자든 나와도 좋다는 의미라고 하였습니다. 그렇다면 HTML의 <img 이후는 .+가 통째로 삼켜버릴 수 있는 부작용이 있습니다. 그런 건 우리가 원하는 결과 아닙니다. .+?는 단지 img 태그명과 src라는 속성 사이에 붙을 수 있는 공백, 혹은 우리의 목적과 관계 없는 속성 부분만을 걸러내기 위한 장치입니다.
- 괄호 부분은 캡쳐라고 하는데, 나오는 순서대로 정규식 내부에서 매칭되는 부분의 문자열을 얻어내기 위한 수단으로 사용되거나 괄호 안의 부분을 우선적으로 적용할 것을 의미합니다. 괄호는 세 번에 걸쳐 있습니다. http:// 가 나오는 부분과 /(.+?\.(jpg|png|gif))) 가 그것입니다. 첫번째(바깥쪽) 괄호는 src 속성의 값을 모두 추출하기 위한 것이고, 두번째(중간) 괄호는 파일 이름만을 추출하기 위한 것입니다. 세번째(가장 안쪽) 괄호는 여러 확장자를 융통성 있게 받아들이기를 위해 사용되었습니다.
- '\.' 처럼 쓴 것은 점이 어떤 문자든 상관 없다는 뜻이 아니라, 정말 '점'으로 사용되기를 원한다는 뜻입니다.
- [0-9]는 0에서 9사이 어떤 한 숫자를 의미합니다. [0-9] 바로 뒤에 '+' 기호가 붙어 숫자가 1회이상 반복됨을 의미합니다.
- \.(jpg|png|gif)는 .jpg거나 .png거나 .gif중 어느 하나이면 된다는 뜻입니다.
- 마지막으로 '.*?>' 부분은 img 태그가 끝나기 전까지 어떤 문자가 있어어도 되고, 없어도 상관이 없다는 말입니다. 다음 태그를 건드리지 않기 위해 ?를 덧붙였습니다.
다운로드 받은 파일에서 정규식이 정말 만화 이미지만 추출하는지 확인해 보도록 하겠습니다.
- extractimgs.py
# -*- coding: cp949 -*- # 정규식을 사용하기 위한 모듈입니다. import re, sys # html에서 만화 이미지 주소를 얻기 위한 함수 def extractimgs(html): exp = re.compile(r'<img.+?src="(http://imgcomic\.naver\.com/webtoon/[0-9]+/[0-9]+/(.+?\.(jpg|png|gif)))".*?>') imgs = exp.findall(html) return imgs # 메인함수 def main(argv): if len(argv) != 2: print 'Usage: extractimgs.py <filename>' return 1 f = open(argv[1], 'r') html = f.read() f.close() imgs = extractimgs(html) if len(imgs) == 0: print >> sys.stderr, "No images!" return 1 for img in imgs: print img[0] # full link print img[1] # file name print img[2] # extension return 0 # 파이썬은 스크립트 언어이므로 C/C++와 같이 main함수를 먼저 실행하지 않습니다. # 본 파일을 실행했을 때 main() 함수가 실행되기 위한 처리를 직접 해야 합니다. if __name__ == '__main__': sys.exit(main(sys.argv))
정확한 정규식의 표현을 적는 것은 꽤 까다로운 일이지만, 정규식을 코드에 사용하는 것은 어렵지 않습니다.
regexp = re.compile(r'<정규표현식>') # 정규표현식 선언, 객체로 만듬 imgs = regexp.findall(html) # html 문자열에서 정규표현식에 부합하는 모든 부분을 img로 리턴
만화 이미지만 저장하기
코드가 올바르게 동작해서 html 문서에서 원하는 만화 이미지의 주소만 얻어낼 수 있었습니다. 이제 각 이미지들을 우리 PC에 저장하는 코드를 작성해야 합니다. 이것은 여러분들에게 숙제로 남겨 두겠습니다. 기존의 urllib2 모듈을 이용해서 각 이미지의 주소에 접속해, 응답 내용을 바로 파일에 쓰기만 하면 됩니다. 이 때 open 함수의 두번째 인자는 'wb'로 바이너리 쓰기를 하게 됨을 잊지 마세요.
끝마치며
파이썬에 흥미를 느끼신 프로그램에 갓 입문하신 분들에게 좋은 실습거리일 것 같아 본 문서를 공개하였습니다. '웹툰'이라는 매체는 엄연히 저작권이 있는 매체입니다. 이를 이용한 실습은 자칫 흥미는 있을지 모르나 웹툰 작가님들과 여러 관계자분들께 누를 끼치는 행위가 되지 않을까 많이 염려하였습니다. 여러 번 밝혔듯 저는 파이썬 학습을 위해 이 문서를 공개하였습니다. 프로그래밍에 대한 순수한 흥미와 호기심만으로 실습을 진행해 주십시오. 이 문서가 전달한 것들은 정말 얕디 얕은 지식에 불과합니다. 이러한 얕은 지식으로 다수에게 누를 끼치는 행위는 삼가하길 간곡히 부탁드립니다.