
목차
멜론 Top 100 차트 내용 추출하기
이번에는 아주 간단한 내용입니다. 국내 음원유통사의 하나인 멜론 차트의 내용을 추출하는 방법을 다루고자 합니다.
일단 멜론 차트의 내용을 추출, 가공했을 때 얻을 수 있는 건 무엇일까요? 일단 겉모양을 쏙 빼고 알짜(콘텐츠)만 있기 때문에 다른 식으로 활용하기 좋습니다. 차트를 바탕으로 어떤 조사를 한다든지, 나름대로의 집계를 할 때 좋을 것입니다. 물론 멜론 가요 차트는 한 예입니다. 이 문서가 보여주는 방법 자체를 응용한다면 웹에 있는 여러 자료(data)를 추출, 가공하여 유용한 정보(information)로 활용하는 것이 가능합니다.
개인적인 의견입니다만, 멜론 웹사이트에는 뭔가 덕지덕지 붙어있는 것이 너무 많습니다. 차트 자체에 눈이 집중되지 않고 산만합니다. 차트 정보만 분석할 목적이라면 본 스크립트를 통해 정보를 받아 엑셀로 보는 게 더 나아 보입니다.
** 이 문서는 2013년 01월의 멜론 웹페이지를 대상으로 하였습니다. 멜론 웹사이트의 개편 등으로 인해 HTML 문서 구조는 변경될 수 있습니다. **
기반 지식
이번에 설명하려는 기반 사항은 매우 단순합니다.
웹 크롤링
지난번 '네이버 웹툰 저장하기' 문서에서 거의 다 언급하였습니다. 그 문서와 이번 문서에서 하려는 내용은 근본적으로는 동일합니다. 다만 지난번에는 정규식을 사용하여 HTML 문서에서 단순하게 링크만을 추출하는 것이 작업의 전부였다면, 이번에는 HTML 문서의 구조를 조금 더 파헤치는 것이 다릅니다. 이렇게 웹에 있는 문서를 수집 분석하는 것은 검색 엔진이 기본적으로 하는 일 중 하나입니다. 이런 것을 '웹 크롤링 (web crawling)'이라고 합니다. 우리가 하는 일은 이 웹 크롤링과 유사합니다만, 특정 목적이 강하지요.
CSV (Comma-Separated Values) 파일
'CSV'라는 용어를 미리 언급하고 넘어가겠습니다.그냥 텍스트 파일이라고 생각하시면 됩니다! 엑셀 같은 스프레드 시트(spread sheet)프로그램이 읽고 쓰는 파일 목록 중 하나입니다.

일반적인 스프레드 시트의 구조를 잠시 언급해 보겠습니다. 위 그림처럼 스프레드 시트의 작업 화면은 행과 열로 나주어져 마치 모눈처럼 되어 있습니다. 사각형 하나를 '셀(cell)'이라고 하는데 하나의 정보, 즉 '값(value)'을 셀에 기록합니다. 각 열은 '필드(field)'라고 부르기도 합니다. 필드는 비슷한 성격을 가진 자료들을 한 범주로 묶는 역할을 합니다. 한 행마다 하나의 자료(record)를 기록하는데, 각 행과 열에 의해 기록하는 정보가 일목요연하게 정리됩니다.
이런 행/열로 구분된 구조 자체를 그대로 텍스트 파일로 기록한 것이 CSV입니다. 한 줄이 한 행이 됩니다. 그리고 각 열을 쉼표(,)로 구분하여 셀의 값을 기록하면 됩니다. 만일 값에 쉼표가 있다면 값의 앞뒤로 따옴표를 기록하여 쉼표를 보호하기도 합니다. 열을 구분하는 역할은 쉼표이기도 하지만 탭, 한 칸 공백, 하이픈 등 논리적으로 필드의 값을 구분할 수만 있다면 어떤 문자를 써도 관계 없습니다. 위 그림의 내용을 CSV 파일 그대로 보면 아래처럼 됩니다.
1,+1,눈물샤워 (Feat. 에일리),배치기,4집 Part.2 2,+1,강북멋쟁이,정형돈,박명수의 어떤가요 3,-2,I`m Sorry,씨엔블루,Re:BLUE 4,0,I Got A Boy,소녀시대,I Got A Boy ... (아래는 값 자체에 쉼표가 있는 경우의 예시) ... 14,-1,이사람,"효린 (씨스타), 전효성, 현아, 정니콜, 나나",2012 SBS 가요대전 The Color Of K-Pop `Dazzling Red`
CSV는 텍스트 파일이지만 데이터의 구조 자체가 엑셀과 같은 스프레드 시트의 그것과 매우 유사합니다. 그러므로 대부분의 스프레드 시트 프로그램은 CSV 파일 읽고 쓰기를 지원합니다. 또한 많은 양의 데이터를 관리하고 활용하는 프로그램에서도 CSV 파일은 대체 저장방법 하나로 활용되고 있습니다.
구현하기
이번에는 HTML 문서를 파싱하기 위해 ' BeautifulSoup'란 파이썬 라이브러리를 사용하도록 하겠습니다. 사실 이 라이브러리만 있으면 다 끝난 셈입니다. 그냥 약간의 HTML 구조만 분석하는 과정만 미리 해 주면 됩니다.
아래 그림은 멜론 차트의 그림입니다. 월간 차트, 주간 차트, 일간 차트 등 여러 차트가 제공됩니다만, 그 구조는 모두 동일합니다. 다른 구조를 사용할 이유가 없긴 하지요.
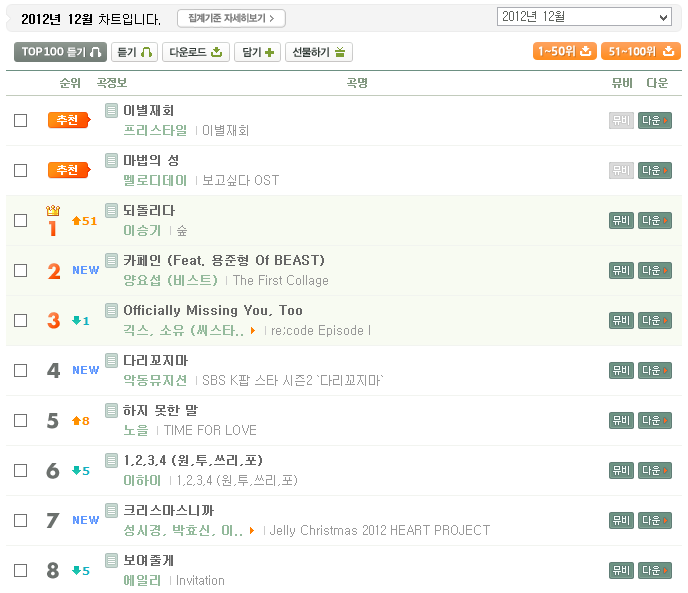
차트의 각 항목 또한 동일한 구조를 가지고 있습니다. 각 차트의 항목은 for-loop과 같은 반복문을 사용하여 프로그래밍되어 있을 겁니다. 당연합니다. 100가지 차트 항목을 일일이 손으로 갱신할 리 없겠죠.
차트의 각 항목은 순위, 등락폭, 곡명, 아티스트 명, 앨범 명이 기재되어 있습니다. 간혹 아티스트 명과 앨범 명의 문자열이 많이 길어질 경우 축약이 되는 경우를 볼 수 있습니다. 이 때 마우스 커서를 축약된 항목에 가져가 보면 전체 내용을 파악할 수 있습니다.
HTML 문서 받아오기
그럼 일단 차트 주소로 접속하여 HTML 문서를 받아오기를 시작해 볼까요?
- get_html.py
# -*- coding: cp949 -*- import urllib2 def get_html(url, maxbuf = 10485760): res = urllib2.urlopen(url) html = res.read(maxbuf) res.close() # HTML을 파일로 저장 #with open('melon_weekly.html', 'w') as f: # f.write(html) # 파일로 저장된 HTML을 로딩 #with open('melon_weekly.html', 'r') as f: # html = f.read() return html if __name__ == '__main__': charturl = {'daily': 'http://www.melon.com/static/cds/chart/web/chartdaily_list.html', \ 'weekly': 'http://www.melon.com/static/cds/chart/web/chartdaily_list.html', \ 'monthly': 'http://www.melon.com/static/cds/chart/web/chartmonthly_list.html'} html = get_html(charturl['daily'])
HTML 문서를 받아오는 일은 식은 죽 먹기입니다. 소스에 HTML 파일을 저장하고 읽어오는 코드가 주석 처리되어 있습니다. 매번 멜론 서버에 접속하기는 좀 그러므로 미리 한 번만 파일로 받아와, 프로그램이 완성되기 전까지는 파일의 HTML 문서로 제작하세요. 괜히 쓸 데 없는 작업으로 인해 서버에 부담을 더 줄 필요가 없습니다. 에티켓은 지켜 주는 것이 좋겠죠.
HTML 문서 분석하기
그럼 이제 저장된 HTML을 열어서 구조를 확인해 보도록 할까요? … 뭔가 엄청납니다. 제가 수집한 차트는 무려 473KiB, 소스 코드의 라인이 무려 4만 3천줄에 달했습니다. 단지 HTML 문서 하나만 말이죠! 일단 파일에 공백이 너무 많습니다. 의미 있는 소스보다 의미 없는 개행이 더 많아 보입니다. 이래서는 원하는 차트가 있는 곳의 구조를 파악하기 무척 어려울 것 같습니다. 어떻게 해야 할까요? 물론 방법이 있습니다. 이제부터 제 나름대로의 요령을 알려드리겠습니다.
파이어폭스 이용하기
파이어폭스에는 '웹 개발 도구'라는 기능이 있습니다. 이것을 이용하면 아주 편리하게 HTML 문서 구조를 파악할 수 있습니다. 웹 개발 도구 중 '문서 검사'를 선택합니다. 차트에 대해 문서 검사를 하면 아래 그림과 같이 마우스로 HTML 문서 요소를 선택할 수 있습니다. 그리고 선택된 문서 요소에 해당하는 태그와 태그의 구조를 파악하기도 매우 쉽습니다. 더구나 '3D 보기' 버튼을 누르면 문서의 내용이 3차원으로도 배열되는데, 이렇게 하면 여러 겹 쌓인 HTML 문서 요소에서 원하는 부분만을 정확히 골라낼 수 있습니다. 아주 편리합니다.
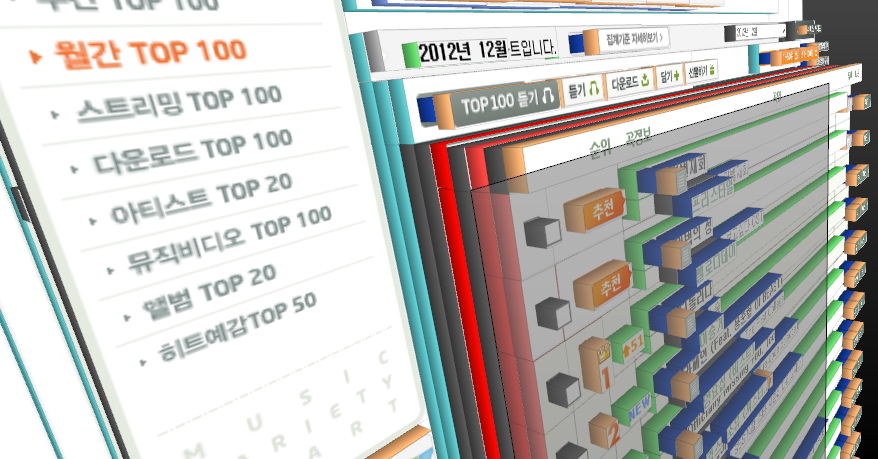
다행히 멜론 차트 HTML 문서는 테이블 범벅인 웹페이지가 아니네요 . 문서는 문서의 ID나 CSS 클래스가 잘 정의되어 있어 탐색하기가 그리 어렵지 않습니다. 문서 검사를 통해 차트가 있는 곳의 태그를 찾아 보았습니다. 이를 탑-다운 방식으로 나열하면 아래처럼 됩니다.
. 문서는 문서의 ID나 CSS 클래스가 잘 정의되어 있어 탐색하기가 그리 어렵지 않습니다. 문서 검사를 통해 차트가 있는 곳의 태그를 찾아 보았습니다. 이를 탑-다운 방식으로 나열하면 아래처럼 됩니다.
html > body > div#wrap > div#container > div#contRight > div#pageList > div#top50, div#top100
하나 주의하셔야 할 점이 있습니다. 파이어폭스 브라우저 문서 검사에 나오는 HTML 소스는 서버가 전달한 HTML 문서 내용 그대로가 아닙니다. 이 소스는 파이어폭스가 한 번 해석해낸 내용(이를테면, DOM)을 다시 HTML로 만들어 낸 것입니다. 우리가 따로 저장한 HTML 문서와 비교해 보면 태그 내의 속성의 순서, 공백문자, 들여쓰기 등이 약간 달라져 있는 것을 확인할 수 있습니다. 물론 문서가 표현하려는 내용 자체가 바뀌진 않겠지요.
웹페이지는 전체 100개의 차트 항목을 두 부분으로 나누어 보여주고 있습니다. 하지만 50개 항목을 볼 때 웹페이지가 갱신되는 것은 아닙니다. 문서에는 1위부터 100위까지 모든 내용을 한꺼번에 저장하고 있으며, 두 부분 중 한 부분은 보이고 다른 한 부분은 감춰지도록 자바스크립트(Javascript)가 제어하고 있을 뿐입니다.
일부분 추출하기
일단 전체 소스는 분량이 너무 많습니다. 그러므로 우리가 필요한 HTML 문서 구조만을 따로 추출하여 저장하는 작업을 먼저 해 보겠습니다. 그리고 원본 HTML 문서 내용은 공백이 너무 많고 들여쓰기도 잘 되어 있지 않아 세부 구조 파악도 어려우니 이를 수정해 보도록 하겠습니다.
이제부터 BeautifulSoup이 활약할 차례입니다. BeautifulSoup의 강력한 기능을 느껴 보세요.
- extract_chart_1.py
# -*- coding: cp949 -*- from bs4 import BeautifulSoup def get_html(): with open('melon_weekly.html', 'r') as f: html = f.read() return html def extract_chart(): html = get_html() # 저장된 파일을 사용합니다. # BeautifulSoup 로 파싱 soup = BeautifulSoup(html) # div 태그 중 id가 top50, top100인 것을 찾아냄 top50 = soup.find('div', id='top50') top100 = soup.find('div', id='top100') with open('top50.html', 'w') as f: f.write(top50.prettify().encode('utf-8')) with open('top100.html', 'w') as f: f.write(top100.prettify().encode('utf-8')) if __name__ == '__main__': extract_chart()
top50.html, top100.html 파일을 열어 보면, 원본 소스와는 다르게 깔끔하게 정리되어 있는 것을 볼 수 있습니다. BeautifulSoup의 prettify() 함수는 지저분한 소스를 깔끔하게 만들어주는 역할을 합니다. 파이어폭스와 마찬가지로 결과물은 BeautifulSoup가 한 번 해석한 것을 다시 HTML 코드로 만들어낸 것입니다. 원본과는 살짝 다릅니다.
소스 코드 접기/펴기
이렇게 들여쓰기가 잘 되어 있는 HTML 코드는 읽기에 매우 편리합니다. 제가 추천하는 Notepad++ 같은 텍스트 에디터들은 이러한 들여쓰기를 해석해 소스 코드 접기/펴기 기능을 제공합니다. 소스 코드 접기를 사용하면 관심있는 소스 부분에만 집중할 수 있어 좋습니다.
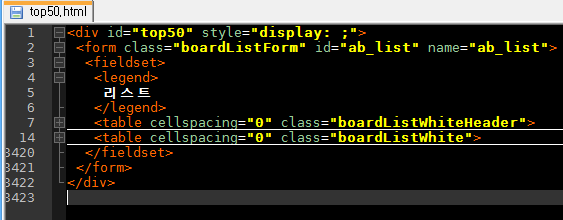
위 그림은 Notepad++로 소스 코드 접기를 한 것입니다. 소스 코드 8번째 줄부터 13번째 줄은 7번째 줄을 기준으로 생략되어 있습니다. 문서 구조상 8번째 줄은 table 태그의 내부이기 때문이지요. 마찬가지로 소스 코드 15번째 줄부터 무려 3419 줄까지는 또다른 table 태그의 내부입니다. 이렇게 소스 코드를 접었다 폈다 하면서 문서 구조를 야금야금 파고 들어가면 됩니다. 상식적으로 1위~50위까지의 차트 내용을 적는데 분량이 적을 리 없습니다. 그러므로 우리가 원하는 차트 내용은 14~3419줄 사이에 있을 것이라고 쉽게 추측할 수 있지요.
잠시 HTML의 table, tbody, tr, td 태그에 대해 언급하겠습니다.
- table 태그는 HTML에서 표를 그릴 때 사용하는 태그입니다. table 태그 내부에 tbody, tr, td 태그를 가지고 있습니다.
- tbody 태그는 테이블의 본문을 지정할 때 씁니다. 반면 테이블의 머리(헤더), 꼬리(푸터)를 지정하기 위한 태그는 각각 thead, tfoot입니다.
- tr 태그는 테이블의 한 행을 지정할 때 사용합니다. 그러므로 tr 태그 사이의 내용은 모두 표의 한 행에 걸쳐 나타나게 됩니다.
- 각 행 내부의 각 열은 td 태그를 이용합니다.
- tr은 행이므로 'table row', td에는 열로 구분된 정보를 적으므로 'table data'라고 기억하면 됩니다.
그럼 14번째 줄의 table 태그부터 원하는 내용을 만날 때까지 점점 하위 계층으로 내려가 보겠습니다. table 태그를 얼마 지나지 않아 tbody 태그가 나옵니다. 그리고 tbody 태그부터 tr 태그가 나옵니다. tbody 태그 내부에 동일한 주석을 가진 tr 태그가 수차례 반복되고 있습니다. 우리가 원하는 내용임에 틀림없습니다. 하나의 tr을 열고 td의 내부 내용은 접어서 td 하위 요소는 생략하여 보도록 하겠습니다. 이렇게 보니 비로소 tr 안의 td 태그의 배열은 두 가지 패턴을 보이고 있는 것을 알 수 있습니다.
그 첫번째 패턴입니다.
<tr> <td class="chk"> <td class="number" colspan="2"> <td> <td class="botn"> </tr>
비슷해 보이지만, 두번째 패턴입니다. 두번째 td의 colspan이 없고 td의 개수가 하나 늘어났습니다. colspan 속성은 2개 이상의 열을 합칠 때 씁니다.
<tr> <td class="chk"> <td class="number"> <td> <td> <td class="botn"> </tr>
첫번째 패턴은 차트의 선두 2행에만 사용됩니다. 이들은 차트 순위와는 관계가 없으며 멜론이 추천하는 곡으로 채워집니다. 3행부터는 모두 두번째 패턴을 사용합니다. 3행부터 차트 순위가 열거됩니다. 첫번째 패턴은 순위와 관련된 내용이 아니므로 처리 대상에서 제외할 것입니다.
두번째 패턴의 각 td(열)에는 다음과 같은 내용이 있음을 확인할 수 있습니다. 가끔 tr에 class=“bg” 속성이 붙기도 하는데 이는 열에 음영처리를 하기 위한 것입니다.
- 첫번째 td는 노래 선택을 위한 체크박스를 담고 있습니다. 내용과는 관계없습니다.
- 두번째 td는 차트 순위 번호를 담고 있습니다. 번호에 다채로운 스타일을 주기 위해 숫자는 모두 img 태그를 이용한 그림을 사용합니다. 다행히 alt 속성에 순위를 텍스트로 표현하고 있습니다.
- 세번째 td는 지난 차트 대비 순위 등락폭을 나타내고 있습니다. td 태그 내부에 span 태그가 있습니다. 화살표 또한 이미지이지만, 숫자와 문자는 텍스트로 표현되고 있습니다. span 태그에 순위가 기록됩니다.
- 순위가 상승했을 때는 class=“up2”라는 속성과 값이 붙고 span 태그 내부에 숫자가 있습니다.
- 순위가 하락했을 때는 class=“down2”라는 속성과 값이 붙고 span 태그 내부에 숫자가 있습니다.
- 새로운 항목이면 class=“entry2”라는 속성과 값이 붙고 span 태그 내부에는 'NEW'라는 문자열이 있습니다.
- 네번째 td 태그에는 곡명, 아티스트 명, 앨범 명이 있습니다.
- td 태그 내부에는 두 개의 span 태그가 있습니다. 각 속성으로 class=“lineLine1”, class=“lineLine2”가 지정되어 있습니다.
- 첫번째 span 태그에 두 개의 a 태그가 발견됩니다.
- 첫번째 a 태그: 곡 상세 정보를 위한 하이퍼링크.
- 두번째 a 태그: 곡 재생을 위한 하이퍼링크.
- 두번째 a 태그의 title 속성의 값을 곡명으로 사용합니다. a 태그의 텍스트를 이용하지 않습니다. 텍스트는 테이블의 레이아웃을 깨뜨리지 않기 위해 축약될 수 있기 때문입니다.
- 두번째 span 태그에도 a 태그가 두 개 발견됩니다.
- 첫번째 a 태그: 아티스트 상세 정보를 위한 하이퍼링크
- 두번째 a 태그: 앨범 상세 정보를 위한 하이퍼링크
- 단 여러 아티스트가 나열될 때는 class=“moreArtistsList”라는 속성과 값을 가진 span 태그가 추가적으로 삽입됩니다. 이 span 태그 내부에는 class=“overList”라는 속성과 값을 가진 span 태그가 하나 더 있으며 여기에 ul, li 태그를 이용해 모든 아티스트를 열거합니다.
- 다섯번째 td 태그는 뮤직비디오나 다운로드를 위한 버튼을 위해 있습니다. 순위와는 관계 없습니다.
이제 거의 모든 정보가 파악되었습니다. 이젠 BeautifulSoup만 믿고 가면 됩니다.
- extract_chart_2.py
# -*- coding: cp949 -*- from bs4 import BeautifulSoup def get_html(): with open('melon_weekly.html', 'r') as f: html = f.read() return html def extract_chart(): html = get_html() # 저장된 파일을 사용합니다. # BeautifulSoup 로 파싱 soup = BeautifulSoup(html) # 이번에는 BeautifulSoup의 CSS를 통해 선택하는 기능을 사용합니다. # 모든 태그 중 boardListWhite CSS 클래스 속성을 가진 태그들을 필터합니다. # 이 CSS 클래스 속성은 차트의 표가 시작되는 table 태그에만 사용되고 있습니다. # 그러므로 tables는 길이 2인 BeautifulSoup의 객체가 담긴 리스트가 됩니다. # 각 객체의 최상위 태그는 html이 아닌 table입니다. tables = soup.select('.boardListWhite') # 1~50위의 각 행과 51위~100위 각 행을 추려냅니다. # top50에는 1~50위 각 tr 태그가 최상위인 BeautifulSoup 객체의 리스트, # top100에는 51~100위 각 tr태그가 최상위인 BeautifulSoup 객체의 리스트가 저장됩니다. top50 = tables[0].tbody.find_all('tr', recursive=False) top100 = tables[1].tbody.find_all('tr', recursive=False) chart = extract_row(top50) chart += extract_row(top100) # chart를 튜플 형태로 (수정불가) 리턴합니다. return tuple(chart) def extract_row(trs): items = [] for tr in trs: # 모든 tr에서 td 항목을 추출해냅니다. tds = tr.find_all('td', recursive=False) # 첫번째 td는 건너뜁니다. # 두번째 td는 랭크 정보인데, 랭크 정보가 숫자가 아니라면 차트 맨 처음의 # 추천곡일 것입니다. 건너뜁니다. alt = tds[1].img['alt'] rank = 0 if alt.isnumeric() == False: continue else: rank = int(alt) # 세번째 td는 순위등락폭입니다. # 순위 등락폭을 +/- 문자로 표시하고, 나머지는 그대로 씁니다. updn = tds[2].span['class'][0] delta = tds[2].span.text if updn == u'up2': delta = u'+' + delta elif updn == u'down2': delta = u'-' + delta # 네번째 td는 곡명, 아티스트명, 앨범명입니다. # 여러 아티스트가 나열되어 있는지를 파악해야 합니다. # td 태그 내부의 title이란 속성을 가진 a 태그만을 추출합니다. links = tds[3].find_all('a', title=True) # overlist라는 클래스 속성을 가진 span 태그를 찾습니다. morelist = tds[3].find('span', class_='overList') # overlist라는 클래스 속성을 가진 span 태그가 발견되면 # 아티스트 이름은 쉼표로 모아 합칩니다. if morelist: song = links[0]['title'] artist = ', '.join([a.text for a in morelist.find_all('a')]) album = links[-1]['title'] else: song = links[0]['title'] artist = links[1]['title'] album = links[2]['title'] # 랭크 하나의 정보가 완료되었습니다. 튜플로 기록합니다. items.append((rank, delta, song, artist, album)) return items if __name__ == '__main__': print extract_chart()
CSV 파일로 저장하기
이제 거의 다 왔습니다. 1위에서 100위까지 순위가 모두 튜플로 전해졌습니다. 남은 것은 CSV 파일로 기록하는 것 뿐입니다. 파이썬 2.3이상에서는 CSV 파일을 읽고 쓰는 라이브러리까지 제공하고 있습니다. CSV 파일 저장까지 끝내고 자잘한 것까지 보탠 최종 코드입니다.
- melon_top_100.py
# -*- coding: cp949 -*- import sys import urllib2 import csv from bs4 import BeautifulSoup def parse_chart(html): soup = BeautifulSoup(html) date = soup.find('div', class_='dateChart clearfix').p.span.text tables = soup.select('.boardListWhite') top50 = tables[0].tbody.find_all('tr', recursive=False) top100 = tables[1].tbody.find_all('tr', recursive=False) #with open('top50.html', 'w') as f: # for item in top50: # f.write(item.prettify().encode('utf-8')) #with open('top100.html', 'w') as f: # for item in top100: # f.write(item.prettify().encode('utf-8')) chart = parse_tr(top50) chart += parse_tr(top100) return date, tuple(chart) def parse_tr(trs): items = [] for tr in trs: tds = tr.find_all('td', recursive=False) # 0th td: Checkbox. No Process # 1st td: Rank. If 'alt' has not a number, skip this tds. alt = tds[1].img['alt'] rank = 0 if alt.isnumeric() == False: continue else: rank = int(alt) # 2nd td: delta updn = tds[2].span['class'][0] delta = tds[2].span.text if updn == u'up2': delta = u'+' + delta elif updn == u'down2': delta = u'-' + delta # 3rd td: song name, artist name, album title. links = tds[3].find_all('a', title=True) morelist = tds[3].find('span', class_='overList') if morelist: song = links[0]['title'] artist = ', '.join([a.text for a in morelist.find_all('a')]) album = links[-1]['title'] else: song = links[0]['title'] artist = links[1]['title'] album = links[2]['title'] items.append((rank, delta, song, artist, album)) return items def get_html(url, maxbuf = 10485760): res = urllib2.urlopen(url) html = res.read(maxbuf) res.close() #f = open('melon_weekly.html', 'w') #f.write(html) #f.close() #with open('melon_weekly.html', 'r') as f: # html = f.read() return html def main(argv): if len(argv) != 2: print u'Usage: python melon_top_100.py [daily|weelky|monthly]' return 0 charturl = {'daily': 'http://www.melon.com/static/cds/chart/web/chartdaily_list.html', \ 'weekly': 'http://www.melon.com/static/cds/chart/web/chartdaily_list.html', \ 'monthly': 'http://www.melon.com/static/cds/chart/web/chartmonthly_list.html'} html = get_html(charturl[argv[1]]) title, chart = parse_chart(html) file_name = title + u'.csv' with open(file_name, 'wb') as f: writer = csv.writer(f, csv.excel) for item in chart: cp949item = [unicode(i).encode('cp949') for i in item] writer.writerow(cp949item) print u'Chart exported to \'%s\'' % file_name return 0 if __name__ == '__main__': sys.exit(main(sys.argv))
만일 엑셀이 설치되어 있다면 CSV 파일을 열어 보세요. 아마 문제 없이 잘 열릴 것입니다. 아래 스크린샷은 소스 결과의 스크린샷입니다.

마치며
멜론 TOP 100 차트를 (엑셀이 다룰 수 있는) CSV 파일로 저장하는 작업을 파이썬을 통해 해 보았습니다. HTML 구조를 분석하고 HTML 문서 구조를 탐색하면서 원하는 정보만을 추출해내는 기법에 대해 간단히 다루어 보았습니다. 웹 문서로부터 특정 정보를 얻어오는 작업 구현을 고려하는 분에게 본 문서가 조금이나마 도움이 되었기를 바랍니다.
/*본 문서에서 사용하는 방법은 특정 컨텐츠와 그 구조에 대해 미리 사전 정보를 사람이 파악하여 프로그램의 사전 정보로써 활용하고 있습니다. 보다 일반적인 자료를 대상으로, 그리고 사람의 작업 없이도 컴퓨터가 알아서 문서의 정보를 추출하고 분류한다면 어떨까요? 무척 복잡한 작업일 것 같습니다. 실제로 구글과 같은 검색 엔진들은 검색에 필요한 기초 자료로서 이러한 작업을 실제로 하고 있습니다. 그리고 이 작업은 검색 엔진의 결과에 중대한 영향을 미칩니다. 현재 우리가 사용 중인 검색 엔진은 꽤 스마트합니다. 한 10년 전의 인터넷 검색 결과를 한 번 되새겨 보시면 알 겁니다. 예전 한미르 광고 아시나요? '핑클'을 찾았는데 결과 1면에 '서핑클럽'이 나온다구요. 그 땐 정말 그랬죠. */
우리가 사용한 BeautifulSoup은 다른 HTML 파서에 비해 약간 속도는 느리지만, 매우 쓰기 편리한 라이브러리입니다. 느리다고는 하지만, 이 정도의 파싱(parsing)이야 사실 순식간입니다. 파싱에 걸리는 시간에 극히 민감한 프로젝트가 아닌 이상 크게 문제가 될 부분은 아니라고 생각합니다. 오히려 본 문서의 프로그램의 수행 시간의 대부분을 차지하는 것은 urllib2가 서버에 접속해서 HTML 문서를 받아오는 과정이지요. 만일 한국이 아닌 해외에서 이 프로그램을 사용한다면 이 폭은 현저히 차이가 나겠죠.
멜론 차트에 익숙해지셨다면, 다른 것도 해 보실 수 있습니다. 엠넷 실시간 차트도 있구요, 크게 한 번 놀아(?) 보시죠? 빌보드 차트는 어떠세요? 비단 차트 뿐만 아니라 평소 자주 접속하여 체크하시는 사이트 또한 대상이 될 수 있습니다. 그 사이트가 RSS나 다른 API를 제공하지 않는다면, 이 문서가 다루는 방법이야말로 제격입니다. 매번 웹브라우저로 접속하지 않고도 정보를 얻을 수 있습니다. 아예 자동화 스크립트 제작도 고려해 볼만하지요.