
목차
웹페이지를 통해 내 PC의 프로그램 상태 모니터링하기
자잘한 파이썬 레시피나 초간단 웹서버 만들기 같은 작은 주제로 글을 쓰려다 보니 이미 저런 내용은 간단히 검색해도 찾을 수 있을 것 같더라구요. 그냥 한데 묶어서 뭔가를 해보는 것이 나을 거 같아서 이런 주제를 정했습니다.
프로그램의 장단점
장점
- 개인 취향이지만, DIY 프로그램치곤 꽤나 재미있고, 때론 유용하다.
- RDP나 VNC 같은 원격접속 프로토콜과 해당 툴들은 여러 플랫폼에서 구할 수 있고, 심지어 스마트폰에서도 쓸 수 있는 앱이 수두룩하다. 하지만,
- 원거리의 경우 인터넷 속도에 크게 좌우된다.
- 주고받는 데이터량이 작업 내용에 비해 많은 편이다. 그러므로 스마트폰의 경우 무제한 요금이 아닌 한 많이 사용하면 요금이 문제가 될 수 있다.
- 반면 이 방법은 간단한 웹페이지므로 다른 피씨, 스마트폰에서도 쉽게 확인 가능하다. 인터넷 상태는 웹페이지 한 번만 로딩할 정도의 상태면 충분하다. 요금 걱정도 크게 줄어들 것이다.
- 다른 PC에 기록될 내 PC에 대한 정보가 최소한으로 줄어든다. 사용 후 웹브라우저에서 방문 기록을 삭제하거나, 아예 '사생활 모드' 등으로 접근하면 만사해결이다.
단점
- 원격접속같이 PC 전반을 건드리거나, 여러 작업을 수행할 수는 없다. 융통성은 떨어질 것이다.
- 보안상의 문제가 생길 수 있다. 웹서버를 만들어서 돌린다는 말은 내 PC에 아무나 들어올 수 있는 길을 하나 터놓는다는 것과 마찬가지다. 우리가 만드는 웹서버는 완전 장난감 웹서버이다. 십중팔구 보안에는 매우 취약할 것이다. 그렇다고, 개인적인 의견이긴 하지만, 가정의 일반 PC에서 까다로울 정도로 보안에 민감해해질 필요는 없다고 본다.
활용 예
사실 다음 상황을 시나리오로 그려 보았습니다. 예를 들어 대량의 자료를 다운로드 받고 있다고 가정하지요. PC를 켜둔 상태로 외출했습니다. 은근히 진행 상태가 궁금합니다. 속도는 얼마나 나오고 있는지, 앞으로 얼마나 더 받아야 하는지, 혹시 문제가 생기지는 않았는지…
인터넷이 빠르고 안정적인 곳이라면 사실 이런 걸 만들 필요가 없을지도 모르겠습니다. 그런데 하루 종일 쉼없이 다운로드 받아봐야 한국에서는 고작 30분에서 1시간 정도면 받아지는 양 밖에 안되는, 인터넷 속도가 매우 느린 곳에 있다고 하면?
바깥에서도 쉽게 다운로드 상태를 모니터링하면 좋겠는데 말이죠. 뭔가 알고 계신 분들은 스마트폰으로 집 PC에 원격 접속을 할 수 있도록 세팅을 해 두셨을 겁니다. 훌륭하십니다. 그런데 네트워크 품질이 영 좋지 않은 곳에서는 원격 접속도 쉽지 않습니다. 더구나 스마트폰 요금이라는 현실적인 제약도 있구요. 이럴 때 이 방법은 조금 수고스럽긴 해도 나름 요긴할 수도 있지 않을까 생각이 들더군요.
해외 교민분들 중 불행히도 인터넷 속도가 많이 느린 지역에 거주하고 있으신 분들께는 혹여 도움이 될 수도 있을지 모르겠네요  피씨를 오래 켜두면서 특정 어플리케이션에 대해 지속적인 모니터링이 필요하신 분 또한 그럭저럭 눈여겨 볼 만한 문서가 될 수도 있을 것 같습니다.
피씨를 오래 켜두면서 특정 어플리케이션에 대해 지속적인 모니터링이 필요하신 분 또한 그럭저럭 눈여겨 볼 만한 문서가 될 수도 있을 것 같습니다.
프로그램 구상
피씨에 아주 작은 웹서버를 돌릴 것입니다. 이 웹서버는 특정 주소에 대해 반응할 겁니다. 사용자가 특정 주소를 입력하면, 피씨에 있는 특정 프로그램의 정보(주로 창에 출력되는 문자열들)를 가져와 웹페이지로 만듭니다. 또 필요에 따라 웹페이지에 폼 요소 등을 삽입할 수 있는데, 이것을 통해 전달된 정보는 피씨에 있는 프로그램으로 전송될 것입니다.
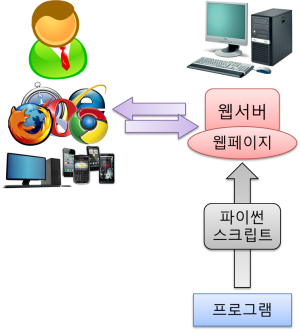
위 그림은 우리가 만들 프로그램에 대한 구상을 그려 본 것입니다. 우리가 짤 파이썬 스크립트는 두 가지입니다.
- 프로그램에서 정보를 추출하는 역할을 맡은 스크립트. 사실 이것은 '파이썬을 이용하여 다른 윈도우 엿보기'에서 소개한 것입니다. 웹서버로부터 특정한 파라미터를 받게 되면 프로그램에게 특정 이벤트를 발동하여 프로그램이 동작하도록 합니다.
- 두번째 스크립트는 아주 간단한 웹서버입니다. 물론 웹서버에 대한 지식이 있으신 분은 아예 잘 만들어진 웹서버(nginx, apache)기반으로하여 프로그램을 완성하실 수도 있을 거란 생각을 합니다. 초보자를 대상으로 웹서버 설정에 대해 설명하면 너무 장황하고 어려울 수도 있고, 지금과 같이 간단한 수준이면 차라리 파이썬으로 만드는 편이 더 쉽습니다.
- 웹서버는 사용자가 보낸 특정 주소 요청에 응답해 프로그램의 상태를 전달합니다.
- 사용자가 보낸 특정 주소 문자열은 첫번째 스크립트에게 특정 파라미터를 전달합니다.
기반 지식
이런 말을 할 자격이 될까 고민이 되지만 살짝 잡설을 늘어놓겠습니다. 개인적으로 한 언어를 능숙하게 쓰는 것보다 더 중요한 것은 언어로 표현하고 싶은 것이 무엇인지를 잘 아는 것이라고 생각합니다. 코드를 능숙하게 짜기 전에 어떤 것이 문제이고, 문제를 해결하기 위해서는 어떤 것이 필요한지, 전제가 되어야 하는지를 파악할 줄 아는 것이 더 우선이라고 생각합니다. 그런 의도로 저는 코드를 먼저 독자에게 들이대지 않는 쪽으로 문서를 구성하고 있습니다. 제 주장에 따르면 코드/프로그램보다 개념/기반지식이 우선이 되므로, 저는 일단 필요한 개념, 기반 지식들을 하나하나 건드려 보고 가고자 합니다. 그러나 깊은 설명은 할 능력도 안 되고, 하고 싶지도 않습니다. 상쾌하기 읽고 넘기면 딱 좋을 문서로 남기고 싶습니다. 짤막짤막하게만 설명하도록 하겠습니다.
그러나 웹, 혹은 웹서버에 대해서는 해야 할 말이 좀 많긴 합니다. 파이썬이 워낙 간결하고 기본 라이브러리가 잘 갖춰져 있어 그냥 코딩 몇 줄이면 후닥닥 해결되는 경우가 많아서 코드에 근간이 되는 숨겨진 개념들을 너무 쉽게 지나치기 쉽습니다. 물론 재미로 하는 우리의 장난감 프로그램을 위해 너무 심각해질 필요는 없지만 너무 주마간산으로 지나치기에는 아쉽다는 생각이 드는군요. 한번쯤은 차근차근 이 문서를 읽어보기를 바랍니다.
네트워크에 대해 약간만
OSI 모델부터, 잡다한 것까지 설명 들어가기 시작하면 이건 네트워크 참고서가 되겠죠. 딱 세가지만 설명하겠습니다. IP 주소, port, 그리고 DNS입니다.
IP 주소와 port에 대해
IP 주소
최근 공유기를 많이 사용하게 되면서 'IP 주소'란 말이 꽤 많이 퍼진 것 같습니다. 정확하게 IP는 'Internet Protocol'의 약자로 프로토콜 자체를 말하는 용어입니다. IP를 간단하게 설명하자면 네트워크에 있는 송신자/수신자가 올바른 경로로 정보를 전달하기 위해 필요한 프로토콜입니다. 'IP'와 'IP 주소'는 엄연히 다르므로 여기서는 구분하여 적도록 하겠습니다.
IP 주소는 네트워크 장비(쉽게 말해 랜카드 등)가 가지고 있는 식별 주소입니다. IPv4, IPv6가 있습니다. IPv6가 새롭게 제안된 프로토콜이지만, 여전히 IPv4가 많이 사용되고 있습니다. 192.168.0.XXX 처럼 0~255사이의 숫자가 네 개 있고 점으로 구분된 형태의 IP 주소는 IPv4입니다. 이 주소에도 체계가 있는데, 그런 것은 생략하도록 하겠습니다.
여러분의 PC가 '인터넷에 연결되어 있다'란 말은 'IP 주소를 (최소한 하나는) 가지고 있다'는 말과 같습니다. 그리고 IP 주소는 유일해야 합니다. 데이터를 올바로 전달하기 위한 것이니 당연히 유일하게 식별할 수 있어야 하지요. 그러나 192.168.XXX.XXX 와 같이 공유기에서 많이 보이는 IP 주소는 '사설 IP'라고 해서 개인적인 네트워크, 쉽게 말해 집 안에서만 유효한 IP 주소입니다. 공유기 밖에 있는 송/수신자에게는 이 사설 IP 주소는 별 의미가 없습니다. 그럼 의미가 있는 주소는요? 공유기가 가지고 있겠죠. 원래 공유기가 한 IP 주소로 여러 개의 네트워크 장치를 사용하기 위해 있는 것이니까요.
Port
IP 주소가 각 PC에 정보를 전달하기 위한 식별 수단이지만, 이것만으로는 아직 체계가 불완전합니다. 실제 우리의 PC에는 상당히 많은 수의 프로그램이 네트워크를 사용하고 있습니다. 한 PC 내부에서도 여러 프로그램이 송/수신중인 데이터를 각기 명확히 식별해낼 수 있는 수단이 필요합니다. 그 수단이 바로 '포트(port)'입니다.
비유를 하자면 이렇습니다. 'A 회사'가 거래처인 'B 회사'에 우편물을 보낸다고 하지요. 그러면 이 우편물은 B 회사의 물류팀이 받을 것인지, 총무과가 받을 것인지, 혹은 인사과에 가야 하는지 명시해야 할 겁니다. 주소상으로는 A 회사의 한 건물에 있을지라도요. 보내는 쪽도 마찬가지입니다. 두 회사가 조그만 구멍가게가 아닌 이상, 주소를 쓸 때에는 <주소>와 <회사 내 소속명>까지 정확히 적어야 할 겁니다. IP주소가 '우편물의 주소'에 해당한다면, 포트는 '회사 내 소속'에 해당한다고 보면 됩니다.
실제로 우리의 PC안에는 여러 프로그램이 동시에 네트워크를 사용중입니다. 웹브라우저로 파일을 전송 받으면서도 메신저로 대화를 할 수 있고 웹서핑도 동시에 가능합니다. 눈에 보이지 않지만 윈도우 시스템은 그 와중에 나름대로 업데이트 서버로부터 업데이트 내용을 알아보고 있을 수도 있구요.
포트 번호의 범위는 0에서부터 65,535까지입니다. 2바이트 부호없는 정수값 범위(0x0000 - 0xFFFF)와 같습니다. 이 중 몇몇은 '잘 알려진 포트(well-known port)'라고 하여 거의 항상 그 프로토콜이 그 번호를 사용합니다. 어떤 것이 있는지 한 번 검색해 보세요. 대표적인 예는 웹서버의 80번 포트입니다.
웹브라우저의 주소를 입력할 때, 예를 들어 '네이버'라고 하면 원래 'www.naver.com:80' 라고 적어야 제대로 웹페이지를 볼 수 있습니다. 그러나 HTTP 웹서버는 거의 80번 포트 번호를 사용하므로, 사용자가 명시하지 않는 이상 웹브라우저는 모두 기본적으로 80번 포트로 접속합니다.
일반적으로 한 PC에서 서로 다른 프로그램이 동시에 하나의 포트 번호를 사용할 수 없습니다. 만약 어떤 프로그램이 이미 사용중인 포트에 접근하려고 한다면 아마 운영 체제 수준에서 에러가 날 겁니다. '아파치' 웹서버가 웹 서비스를 위해 80번 포트를 사용하고 있다면, '톰캣' 서버는 이미 점유된 80번 포트 대신 다른 포트 번호를 사용해야 합니다. 주로 8080번 포트를 사용하곤 하지요. 반드시 달라야 합니다.
DNS 에 대해
각 PC를 구분하기 위해 IP 주소를 사용하는데, 사실 우리가 웹서버에 접속하는데 IP 주소를 쓰는 일은 거의 없습니다. 여러분 중 '구글'에 접속하기 위해 'gooogle.com'이란 도메인 이름(domain name) 대신 '173.194.37.146'으로 들어가는 분 있으신가요? :) 둘 다 구글의 서버에 접속할 수 있긴 합니다.
이건 이렇게 비유할 수 있지요. 기본적으로 전화를 걸 때는 전화 번호를 하나하나 적어서 걸어야 하지요. 하지만 전화기가 조금 좋아지면서 자주 쓰는 번호는 단축 다이얼에 넣을 수 있게 되었습니다. 이보다 훨씬 좋아진 전화기들은 주소록으로 연락처를 관리합니다. 주소록을 이용하면 이름, 집 전화, 직장 전화, 개인 휴대전화, 이메일까지 관리할 수 있어 아주 편하지요. 요즘은 굳이 전화 번호를 외우고 다니지 않습니다. 사람 이름으로 찾거나 단축 다이얼을 눌러 전화를 걸지요.
전화번호와 도메인 이름의 개념은 이처럼 거의 같습니다. 그러나 전화번호의 경우 지극히 개인적인 사항이므로 주소록을 각자의 폰에 각자가 관리합니다. 그러나 도메인 이름은 모두가 공통적으로 사용하니 한 데 모아서 관리하는 것이 유용하고, 또한 그렇게 하고 있습니다. 도메인 이름의 주소록, 이 주소록 체계를 일컬어 'DNS(Domain Name System)'라고 합니다. DNS 서버는 도메인 이름을 관리하는 서버입니다. 질의한 도메인 이름에 대해 연결된 IP 주소를 알려주는 중요한 역할을 합니다.
눈에 보이지 않지만 사실 'google.com'을 웹브라우저에서 입력하면 웹브라우저는 사실 DNS 서버에 질의해서 얻어낸 google의 IP 주소로 접근합니다. google.com의 도메인 이름이 하는 역할은 딱 여기까지입니다. 사람이 알아보기 쉽다는 이점이나 관리상의 이점이 있는 거지 'google.com'이란 이름 자체에 뭔가 특별한 의미가 있는 것은 아닙니다. 전화를 걸 때 전화번호가 중요하지 주소록의 이름은 어쨌든 상관없는 것과 같은 이치입니다.
참고로 여기서 관리상의 이점이란 쉽게 말해 이렇습니다. 새로운 서버를 도입하면서 IP 주소가 변경되는 일이 피치 못해 생겼습니다. IP 주소를 그대로 쓰는 경우였다면 IP 주소가 바뀌었다는 사실을 동네방네 알려야 할 겁니다. 그러나 도메인 이름을 사용한다면 도메인 이름에 대응되는 IP 주소 기록만 살짝 변경해주면 그만입니다. 도메인 이름이 변경되지 않는 이상 접속하는 사람들은 IP 주소에 대해 아예 신경 쓸 필요도 없이 계속 서비스를 이용할 수 있겠죠.
명령 프롬프트에서 'nslookup naver.com'이라고 입력해 보세요. naver.com의 IP 주소를 DNS 서버에 질의하기 위한 명령입니다. 아마 '220.95.233.171'을 비롯한 몇 개의 IP 주소가 응답으로 돌아올 것입니다. 대형 업체는 이렇게 한 도메인 이름에 여러 IP 주소를 사용하기도 합니다.
각 인터넷 업체마다 각각 DNS 서버는 다를 수 있습니다. 대표적으로 KT의 DNS 서버 주소는 '168.126.63.1', '168.126.63.2'입니다. 구글에도 DNS가 있는데 '8.8.8.8', '8.8.4.4'입니다. DNS 서버는 도메인 이름을 알기 위한 기본적인 서버이므로 도메인 주소가 없습니다. IP 주소로만 접속이 가능합니다.
웹페이지에 대해 약간만
이 장에서는 웹페이지에 대한 주변 지식을 간단히 정리해보도록 하겠습니다. 어째서 웹페이지가 서버로부터 내 PC에 전달이 되는지, 어째서 웹브라우저에서 내가 클릭한 항목에 대해 페이지 이동이 가능한지에 대해 한 번쯤 의문을 가져 보셨다면 본 문서가 약간 도움이 될 것입니다.
HTTP Request, response 메시지
HTTP 문서가 PC에서 보여지기 위해서는 먼저 서버에 '요청(request)'을 해야 합니다. 당연한 이야기입니다. 말하지도 않았는데 알아서 무언가 해 주는 일은 없겠죠. 요청을 했으면 그 요청에 대해 '응답(response)'이 있어야 합니다. 이것도 당연한 이야기입니다. 사실 터무니없는 이야기를 바탕으로 프로그램을 만들 수는 없긴 하죠 :) 문제는 그 요청과 응답이 어떻게 이루어지는가입니다.
서버와 클라이언트는 이 요청과 응답을 아주 단순한 방법으로 수행하고 있습니다. 서버와 클라이언트 둘 다 각각 보내는 메시지에 '헤더(header)'라는 부가적인 정보를 메시지 앞에 붙여서 보냅니다. 이 메시지는 일반적으로 웹브라우저에서는 보이지 않습니다.
자, 그렇다면 보이지 않던 헤더를 적접 눈으로 확인해 보도록 하겠습니다. HTTP Web-Sniffer에 접속해보세요. 웹에서 바로 HTTP 요청과 응답 헤더를 확인할 수 있습니다. 자 여기서 구글에 접속해볼까요? 'HTTP(S)-URL'에 'http://www.google.com'을 입력하고 'Submit'을 누릅니다.
다음은 Web-Sniffer가 출력한 요청 헤더입니다.
GET / HTTP/1.1[CRLF] Host: www.google.com[CRLF] Connection: close[CRLF] User-Agent: Web-sniffer/1.0.44 (+http://web-sniffer.net/)[CRLF] Accept-Encoding: gzip[CRLF] Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8[CRLF] Accept-Language: ko-kr,ko;q=0.8,en-us;q=0.5,en;q=0.3[CRLF] Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7[CRLF] Cache-Control: no-cache[CRLF] Referer: http://web-sniffer.net/[CRLF] [CRLF]
[CRLF]는 \r\n를 말하는 겁니다.
다음은 서버에서 보낸 응답 헤더입니다. 첫 줄의 'Status: HTTP/1.1 200 OK'라는 문자열을 보니 서버가 정상적으로 클라이언트에 응답한 것으로 보이네요. '200'과 같은 숫자는 서버가 클라이언트에게 보내주는 전송 상태에 대한 코드입니다. 'HTTP status code'로 검색하면 보다 많은 값들을 확인할 수 있습니다. 대표적인 상태 코드로 성공 코드인 '200 OK', 잘못된 문서에 대한 접근인 '404 Not Found', 가끔 서버에 문제가 발생한 경우 보이는 '502 Bad GateWay'등이 있습니다.
| 헤더이름 | 값 |
|---|---|
| Status: HTTP/1.1 200 OK | |
| Date: | Sat, 22 Dec 2012 01:54:11 GMT |
| Expires: | -1 |
| Cache-Control: | private, max-age=0 |
| Content-Type: | text/html; charset=EUC-KR |
| Set-Cookie: | PREF=ID=50acc491b78dbdb3:FF=0:TM=1356141251:LM=1356141251:S=ol0qyWety5nMVdhM; expires=Mon, 22-Dec-2014 01:54:11 GMT; path=/; domain=.google.com |
| Set-Cookie: | NID=67=I8mgJBKl6jw0P1LLYhc7SCAM3xZ7hJJQPjaw7q6y7Ifnt6yh1LBxRzFjBQ3_7-8f6yzXG4KHDcX1oIM55RRkk3uYoCncoeC7WDrk6KTBtzvdEtDcGmFbrfqQ_6973EHS; expires=Sun, 23-Jun-2013 01:54:11 GMT; path=/; domain=.google.com; HttpOnly |
| P3P: | CP=“This is not a P3P policy! See http://www.google.com/support/accounts/bin/answer.py?hl=en&answer=151657 for more info.” |
| Server: | gws |
| X-XSS-Protection: | 1; mode=block |
| X-Frame-Options: | SAMEORIGIN |
| Connection: | close |
Content 영역은 아래와 같이 출력됩니다.
<!doctype html><html itemscope="itemscope" itemtype="http://schema.org/WebPage"><head>...
Content 영역은 우리가 웹브라우저에서 '소스 보기'를 했을 때 볼 수 있는 HTML 문서입니다.
위 헤더의 내용을 다 알 필요는 없습니다. 말씀드리고자 하는 바는 서버와 클라이언트 사이에 지금까지 눈에 보이지는 않았지만 이렇게 약속된 메시지를 주고 받는다는 사실이며, 그 메시지가 사람도 이해할 수 있는 형태란 것입니다.
웹브라우저가 화면에 보이는 것처럼 웹페이지를 만들기 위해서는 우선 HTML 문서를 분석해서 컴퓨터가 HTML 문서를 이해하는 작업이 필요합니다. 이를 흔히 'HTML 파싱(parsing)'이라고 합니다. HTML 파싱을 통해 웹브라우저는 어떤 CSS가 쓰였는지, 자바스크립트 파일은 어디에 있는지, 이미지 파일은 어디서 가져와야 하는지, 플래시와 같은 플러그인들을 사용하는지를 이해합니다.
이후 위와 유사한 요청/응답 메시지를 몇 번 더 주고받아 CSS 파일, 자바스크립트 파일, 이미지 파일 및 플러그 파일들을 다운로드 받습니다. 그리고 이 파일들을 웹브라우저의 화면에 HTML 코드가 지시하는대로 그려서 문서를 완성합니다. 이러한 과정을 '렌더링'이라고 합니다.
최근 웹브라우저들은 이렇게 HTML 파일을 얼마나 빠르게, 잘 표현하는지로 첨예한 경쟁을 벌이고 있습니다.
Form과 POST
서버에서 클라이언트로 정보(HTML 문서)를 보내는 형태가 대부분이지만, 때로는 클라이언트에서 서버로 정보를 보내야 할 때가 있습니다. 이 정보는 링크 주소와 같이 일방적으로 단순하게 정해져 있는 경우도 있지만, 클라이언트 쪽에서 여러 가지를 결정해야만 하는 경우도 있습니다. 우리는 흔히 어떤 사이트에 가입을 할 때나 글을 적을 때 이러한 요소들을 많이 보아왔습니다. 장문의 텍스트를 적을 때는 텍스트 상자를, 짧은 글을 입력할 때에는 입력 상자를, 버튼을 누를 때에는 버튼 상자를, 어떤 정해진 요소 중 하나를 골라야만 할 때에는 라디오 버튼이나 콤보 상자를 이용합니다.
이렇게 사용자가 좀더 손쉽고 실수 없이 서버에 필요한 정보를 입력할 수 있도록 한 장치를 '폼(Form)'이라고 부릅니다. 폼에 값을 입력하고 '전송(Submit)' 버튼을 누르면 서버로 데이터가 넘어갑니다. 이 때 주소에 모든 정보가 담기는 것을 'GET' 방식이라고 하였습니다. 그래서 GET 방식으로 보낸 데이터들은 웹브라우저의 주소창을 보면 확인할 수 있습니다.
하지만 때로는 웹브라우저의 주소창에 깨끗하게(?) 아무런 정보가 없이 사이트의 주소만 있는 경우가 있습니다. 어떤 사이트에 로그인을 할 때가 그 좋은 예이지요. 아이디와 비밀번호를 입력하면 분명히 그 두 정보는 서버로 전달되었을텐데, 주소창엔 아이디와 비밀번호에 대한 어떤 정보도 표시되지 않습니다. 아니, 표시되면 안되겠죠.
이렇게 주소창에 표시되지 않고 서버로 넘어가는 방식을 일컬어 'POST 방식'이라고 합니다. 그러면 POST 방식에서는 폼의 정보를 어떻게 서버로 넘길까요? 이것은 Web-Sniffer에서는 보기 어려우므로 파이어폭스 웹브라우저의 확장 기능인 'HttpFox'를 통해 확인해보도록 하겠습니다. 이 확장기능은 Web-Sniffer와 마찬가지로 브라우저가 송/수신하는 메시지의 헤더 정보를 열람할 수 있도록 합니다.
이 기능을 통해 서버로 보내는 요청 메시지를 살짝 엿보도록 하겠습니다. 다음은 제가 클리앙에 로그인할 때의 요청 헤더를 엿본 결과를 발췌한 것입니다.
(Request-Line) POST /cs2/bbs/login_check.php HTTP/1.1 Host www.clien.net User-Agent Mozilla/5.0 (Windows NT 6.2; rv:17.0) Gecko/20100101 Firefox/17.0 Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language ko-kr,ko;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding gzip, deflate Connection keep-alive Referer http://www.clien.net/?nowlogin=1 Content-Type application/x-www-form-urlencoded Content-Length 71
여기서 다음 두 라인을 주목해야 합니다.
POST /cs2/bbs/login_check.php HTTP/1.1
Content-Type application/x-www-form-urlencoded
로그인 할 때 POST 방식으로 데이터를 전송한다는 것을 첫 번째 줄이 확실히 보여줍니다. 두번째 줄은 클라이언트가 서버로 어떤 내용(콘텐츠)를 보낸다는 의미입니다. 그 내용이 다음과 같습니다.
url=%252F%253Fnowlogin%253D1&mb_id=*********&mb_password=**************
제 아이디와 비밀번호는 가렸습니다. 하마터면 제 아이디와 비밀번호가 그대로 노출될 수도 있겠네요. 누군가 제 통신 내용을 엿본다면 클리앙의 아이디와 비밀번호는 고스란히 그 사람의 것이 될 겁니다.
현재 많은 사이트들이 이런 방식의 로그인을 사용중입니다. 이러한 방식은 사용자가 보안에 주의해야 합니다. 클리앙의 로그인 방식에 대해 왈가왈부하고자 하는 의도는 일절 없으며, 단지 POST 방식으로 전달되는 폼 양식은 이렇게 전송되는 메시지 본문(내용)에 있다는 것을 보여주고자 예를 들었습니다.
한편 수많은 이들이 사용하는 대형 포털 사이트의 로그인에는 이러한 일을 막기 위해 '보안 접속'이란 장치를 마련해 두고 있습니다. 보안 접속으로 로그인하면 이렇게 아이디와 비밀번호가 고스란히 노출되는 일은 없습니다.
Server-side Script
서버에서는 클라이언트로 입력받은 정보를 처리한다거나, 데이터베이스에 접속한다거나 하는 복잡한 일들을 뒤에서 수행하고 있습니다. 이렇게 하려면 프로그램이 필요하지요. 서버 측에서 이러한 메시지를 능동적으로 해석하고 처리하기 위한 프로그램을 Server-side script라고 합니다. JSP나 PHP등은 대표적인 서버측 스크립트 언어입니다.
Client-side Script
서버측 스크립트의 반대 개념으로, 클라이언트에서 동작하는 스크립트입니다. '자바스크립트(Javascript)'가 그 선두주자이죠. 사족이지만 자바스크립트는 '자바(Java)'와는 이름만 비슷하지 전혀 관계 없는 언어입니다. 클라이언트측 스크립트를 이용하면 클라이언트의 HTML 문서에서 문서의 요소를 동적으로 변화시킬 수 있습니다. 버튼을 누르면 메시지 상자가 나타나는 것, 버튼을 클릭하면 글자색이 바뀌거나 배경색이 바뀌는 것들이 그러한 예입니다. 이렇게 동적인 HTML 문서를 'DHTML'이라고 부르기도 합니다.
일반적으로 자바스크립트는 사용자의 PC의 접근에 제한을 받습니다. 악의를 가진 자바스크립트가 멋대로 사용자의 PC를 헤집고 다닐 수 없도록 말이죠.
하지만 때로는 사용자의 PC의 파일에 대해 읽고 쓰기를 허용해야 할 때가 있는데, 이를 위해 플러그인이 이용됩니다. 플러그인의 대표적인 예로는 '플래시(Flash)', '자바 애플릿(Java Applet)', 그리고 악명 높은 '액티브엑스(ActiveX)' 등이 있습니다. 사용자의 PC에 대해 자유로운 접근이 가능하므로 이러한 플러그인은 주의를 기울여야 합니다. 웹브라우저들이 이들을 쓰려고 할 때마다 사용자들을 살짝 귀찮게 하는 것도 바로 이러한 이유에서라 할 수도 있겠습니다. 이 중 액티브엑스는 윈도우 데스크탑 운영체제에서만 동작하도록 제작되어 제약이 많음에도 불구하고 한국에서는 유독 많이 쓰이고 있지요. 
Basic Access Authentication
자 이제 마지막으로 '인증'에 관해 짤막하게 설명하고 넘어가겠습니다. 가끔 어떤 웹사이트에 가면 아래와 비슷한 창을 띄우며 인증을 요구합니다.
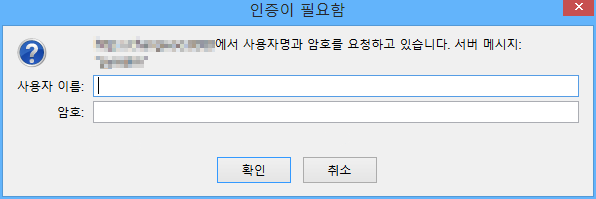
이 방식을 이용하면 서버와 클라이언트 사이에 오가는 헤더 정보만으로 간단하게 인증을 할 수 있어 매우 편리합니다. 별다른 플러그인이나 장치를 필요로 하지도 않아서 심플하기도 합니다. 혹여 웹페이지의 정보가 쉽게 노출되는 것이 꺼려진다면 이것으로 나름대로 보호할 수 있습니다. 그러나 이 방식 또한 보통 로그인처럼 아이디와 비밀번호가 노출되므로 주의해야 합니다. 더 강력한 보호를 위해서는 더 많은 보안 시스템을 도입해야 합니다.
인증은 이렇게 이루어집니다. 클라이언트가 인증되지 않은 채로 서버에 접근하면, 서버는 클라이언트에 신원을 요구합니다. 서버는 클라이언트에게 401번 응답 코드와 아래와 같은 헤더를 클라이언트에 보냅니다. 이것이 서버가 인증을 요구하는 방식입니다. 헤더 한 줄이면 됩니다.
WWW-Authenticate: Basic realm="서버 메시지"
그러면 웹브라우저에서는 위 그림과 같은 인증 창이 나옵니다. 사용자 이름(아이디)와 비밀번호를 입력하고 전송하면 클라이언트에서는 서버로 다음과 같은 헤더를 보냅니다.
Authorization: Basic <아이디:패스워드를 Base64로 인코딩한 문자열>
예를 들어 클라이언트가 보내는 사용자 이름이 'abc'이고 비밀번호가 '1234'라고 가정합시다. 클라이언트는 사용자 이름과 비밀번호를 콜론(':')으로 구분한 하나의 문자열로 합칩니다. 한 문자열인 'abc:1234'는 Base64라는 인코딩 방식을 통해 'YWJjOjEyMzQ='로 전달됩니다. Base64는 단순한 방법으로 한 문자열을 다른 문자열로 변경합니다. 특별한 암호화는 아니므로 방법만 알면 누구나 인코딩/디코딩이 가능합니다. 이에 관해서는 따로 검색을 해 보세요.
서버는 클라이언트가 받은 'Authorization'헤더의 값에 대해 Base64 디코딩을 수행해 원래의 사용자 이름과 비밀번호를 복구합니다. 그래서 자신이 가진 리스트 중에 사용자가 입력한 이름과 비밀번호 쌍이 있는지 확인하지요. 확인이 되면 인증이 되는 겁니다. 아니면 서버의 페이지를 볼 수 없는 것이구요. 엄밀히 말하면 서버의 서버측 스크립트가 미리 잘 프로그램하여 항상 그렇게 되도록 장치를 마련해 두어야 하는 것이지만요. 알아서 자동으로 해 주는 일은 없습니다. 메시지에 대해 처리하지 않으면 인증이고 무엇이고 있으나마나입니다.
웹서버 스크립트 만들기
웹서버 동작시키기
이제 파이썬 스크립트를 직접 제작하여 실습을 하는 시간입니다.
기본 웹서버 동작시켜 보기
파이썬에서 웹서버를 만드는 것은 정말 식은 죽 먹기입니다. 파이썬에서 웹서버는 언제든 사용할 수 있도록 기본 라이브러리에서 제공이됩니다. 그럼 당장 파이썬의 내장 웹서버를 동작해볼까요?
python -m SimpleHTTPServer 8000
이 한 줄로 웹서버가 동작합니다. 개인적으로 urllib으로 웹페이지 소스를 읽어올 때만큼 충격적인 한 줄이었지요 
파이썬 기본 웹서버는 파이썬이 실행된 경로의 파일과 디렉토리의 목록을 출력합니다. 실행 후 웹브라우저에서 'localhost:8000'으로 접속해 확인해보세요.
기본 웹서버를 상속받아 수정하기
기본 웹서버는 우리가 원하는 동작을 수행하지 않습니다. 우리는 특정 문자를 입력받아서 프로그램의 상태를 보여 주는 서버를 만들어야 합니다. 그러므로 기본 웹서버 클래스를 상속받아 우리만의 웹서버로 만들어야 합니다. 일단 가장 기본적인 기능만 동작시켜 보도록 하지요.
- MonitorServer_01.py
# -*- coding:cp949 -*- from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler import sys class MyRequestHandler(BaseHTTPRequestHandler): def do_GET(self): try: addr, port = self.client_address print "Connection from", addr, "port", port print "Request header:" print self.headers urlpath = self.path if urlpath == '/status.html': self.send_response(200) self.end_headers() f = open(urlpath[1:], 'r') self.wfile.write(f.read()) f.close() else: raise IOError except IOError: self.send_error(404, 'File not found: %s' % self.path) def log_message(self, format, *args): pass # 로그 메시지 끄고 조용히 하기 위함 # 상태 보고 서버를 시작함 def StartStatusServer(port): httpd = HTTPServer(('', port), MyRequestHandler) try: print "Status server started." httpd.serve_forever() except KeyboardInterrupt: print "Status server finished." def main(argv) : if len(argv) != 2: print >> sys.stderr, "Usage: MonitorServer_01.py <port number>" return 1 port = int(argv[1]) StartStatusServer(port) return 0 if __name__ == '__main__' : sys.exit(main(sys.argv))
- status.html
<h1>Hello!</h1> <p>This is our content!</p>
두 파일을 같은 경로에 놓고 실행을 합니다. 스크립트는 포트 번호를 인자로 받습니다. 적당한 포트 번호를 입력하고 서버를 동작시키면, 서버는 대기 상태에 들어갑니다. 웹브라우저를 열어 'localhost:<포트>/status.html'을 입력해보세요. HTML 문서가 출력되면 성공입니다. 현재 웹서버는 status.html 만 허용하도록 되어 있지만, 뭐 이것만으로도 충분합니다.
웹서버에 사용자 인증 기능 추가하기
웹페이지의 내용을 보호하하기 위해 기본 인증 방식을 이용해서 '로그인' 기능을 흉내내도록 하겠습니다. 앞서 Basic Access Authentication에서 설명하였듯, 클라이언트는 인증을 위해 'Authorization' 필드를 헤더에 삽입해 서버로 보냅니다. 서버는 이 헤더 메시지에서 해당 항목을 찾고, 보이지 않으면 클라이언트에 인증을 하라는 요청을 할 것입니다. Authorization 필드가 존재한다면 필드의 값을 보고 인증을 시도할 겁니다.
여기서 미리 한가지 문제를 미리 제기하고 시작하겠습니다. 기본 인증 방식은 '로그아웃'은 따로 존재하지 않습니다. 로그아웃을 하려면 브라우저를 완전히 꺼야 합니다(탭 브라우징이 가능한 웹브라우저라면 모든 탭을 완전히 닫아서 종료를 해야 합니다.). 그렇지 않으면 기록이 남아 있어 여전히 페이지에 접근이 가능합니다. 사용하시면서 절대 잊어버리지 말아 주십시오.
다음은 초라하나마 사용자 인증 기능을 추가하여 완성한 우리의 서버입니다.
- MonitorServer_02.py
# -*- coding:cp949 -*- from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler import base64 import sys class MyRequestHandler(BaseHTTPRequestHandler): def do_GET(self): try: addr, port = self.client_address print "Connection from", addr, "port", port print "Request header:" print self.headers urlpath = self.path if urlpath == '/status.html': if self.login_process() == True: self.send_response(200) self.send_header('Connection', 'Closed') self.send_header('Content-Type', 'text/html') self.end_headers() f = file('status.html', 'r') self.wfile.write(f.read()) f.close() else: self.response401() self.wfile.write('<P>Login Canceled.</P>') else: raise IOError() except IOError: self.send_error(404, 'File not found: %s' % self.path) def log_message(self, format, *args): pass # 로그 메시지 끄고 조용히 하기 위함 def login_process(self): if self.headers.has_key('Authorization'): authm, val = self.headers['Authorization'].split() userid, passwd = base64.b64decode(val).split(':') # print userid, passwd if userid == 'guest' and passwd == 'guestpass': return True return False def response401(self): self.send_response(401) self.send_header('WWW-Authenticate', 'Basic realm=\"pyrealm\"') self.send_header('Content-Type', 'text/html') self.send_header('Connection', 'Closed') self.end_headers() # 상태 보고 서버를 시작함 def StartStatusServer(port): httpd = HTTPServer(('', port), MyRequestHandler) try: print "Status server started." httpd.serve_forever() except KeyboardInterrupt: print "Status server finished." def main(argv) : if len(argv) != 2: print >> sys.stderr, "Usage: MonitorServer_02.py <port number>" return 1 port = int(argv[1]) StartStatusServer(port) return 0 if __name__ == '__main__' : sys.exit(main(sys.argv))
타겟 윈도우 정보 추출 프로그램 만들기
타겟 프로그램 정하기
타겟 프로그램은 어떤 것이라도 상관없습니다만, 저는 파이썬을 이용하여 다른 윈도우 엿보기와 마찬가지로 'TeraCopy' 프로그램을 대상으로 하였습니다. 각자 마음에 드는 프로그램을 골라 타겟으로 정하면 됩니다.
타겟 프로그램의 윈도우 정보를 출력하기
타겟 프로그램의 생김새는 다음 그림과 같습니다.
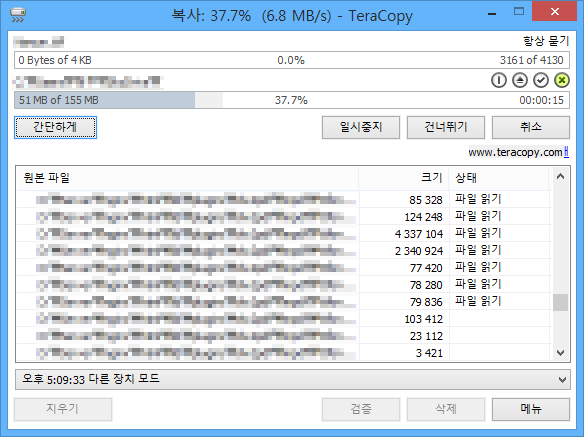
타겟 프로그램을 작업관리자에서 확인하여 프로그램에 위치한 컨트롤의 리스트를 출력해봅니다. 저는 그다지 수정할 것이 없군요. 이 프로그램에서 가장 의미있는 부분은 파일의 리스트가 나오는 부분입니다. 이 부분은 5개의 열로 되어 있으므로 5개 열 각각을 리스트로 모두 가져오도록 하겠습니다.
enumlistwindow.py를 기반으로 해서 새로운 프로그램을 만들어 보겠습니다. 얼개는 같습니다만, 이 프로그램은 리스트를 HTML 파일로 출력합니다. 하드코딩된 HTML 출력 부분을 보니 왠지 짠합니다.
- report_status.py
# -*- coding:cp949 -*- # TeraCopy 내부의 모든 윈도우 객체를 나열합니다. import win32gui import win32con import commctrl import pywintypes import struct, array import sys from ListViewItems import GetListViewItems # 부모 윈도우의 핸들을 검사합니다. class WindowFinder: def __init__(self, windowname): try: win32gui.EnumWindows(self.__EnumWindowsHandler, windowname) except pywintypes.error as e: # 발생된 예외 중 e[0]가 0이면 callback이 멈춘 정상 케이스 if e[0] == 0: pass def __EnumWindowsHandler(self, hwnd, extra): wintext = win32gui.GetWindowText(hwnd) if wintext.find(extra) != -1: self.__hwnd = hwnd return pywintypes.FALSE # FALSE는 예외를 발생시킵니다. def GetHwnd(self): return self.__hwnd __hwnd = 0 # 자식 윈도우의 핸들 리스트를 검사합니다. class ChildWindowFinder: def __init__(self, parentwnd): try: win32gui.EnumChildWindows(parentwnd, self.__EnumChildWindowsHandler, None) except pywintypes.error as e: if e[0] == 0: pass def __EnumChildWindowsHandler(self, hwnd, extra): self.__childwnds.append(hwnd) def GetChildrenList(self): return self.__childwnds __childwnds = [] # teracopy의 보고 기능 class teracopy_reporter: def __init__(self, windowname): self.__GetChildWindows(windowname) # windowname을 가진 윈도우의 모든 자식 윈도우 리스트를 얻어낸다. def __GetChildWindows(self, windowname): # TeraCopy의 window handle을 검사한다. self.__hwnd = WindowFinder(windowname).GetHwnd() # Teracopy의 모든 child window handle을 검색한다. self.__childwnds = ChildWindowFinder(self.__hwnd).GetChildrenList() # 리스트 뷰 컨트롤의 텍스트를 파일로 저장합니다. def report_status(self, save_as): listviewCtrl = 0 for child in self.__childwnds: wnd_clas = win32gui.GetClassName(child) if wnd_clas == 'SysListView32': listviewCtrl = child break item_grid = [] for i in range(5): column = GetListViewItems(listviewCtrl, i) item_grid.append(column) # html로 쓰기 html = '' with open(save_as, 'w') as f: html += "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd\">\n" html += "<html>\n\t<head>\n\t\t<meta http-equiv=\"content-type\" content=\"text/html; charset=euc-kr\" />\n" html += "\t\t<title>TeraCopy Status</title>\n\t</head>\n" html += "<body>\n\t<table border=\"1\">\n" html += "\t\t<tr>\n" html += "\t\t\t<th>원본파일</th>\n" html += "\t\t\t<th>크기</th>\n" html += "\t\t\t<th>상태</th>\n" html += "\t\t\t<th>원본 CRC</th>\n" html += "\t\t\t<th>대상 CRC</th>\n" html += "\t\t</tr>\n" for r in range(len(item_grid[0])): html += "\t\t<tr>\n" html += "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" % \ (item_grid[0][r], item_grid[1][r], item_grid[2][r], item_grid[3][r], item_grid[4][r]) html += "\t\t</tr>\n" html += "\t</table>\n" html += "</body>\n</html>\n" f.write(html) __hwnd = 0 __childwnds = 0 if __name__ == '__main__': tr = teracopy_reporter('TeraCopy') tr.report_status('tr.html')
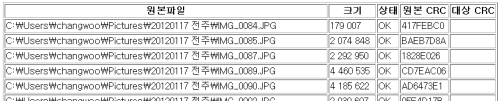
출력 결과의 일부입니다.
타겟 프로그램의 이벤트 메시지 분석
Spy++에는 이벤트 메시지를 분석하는 기능도 있습니다. 'Spy→Windows'를 선택한 후, TeraCopy의 윈도우를 찾습니다. TeraCopy에는 파일 목록을 보이게도 숨기게도 하는 '더 보기/간단하게' 버튼이 있습니다. 이 버튼을 동작시키는 메시지의 정체를 Spy++를 통해 확인해 보도록 하겠습니다.
일단 클릭해보니 '더 보기/간단하게' 버튼은 같은 스레드이며, 버튼에 있는 글자만 달라질 뿐이란 걸 쉽게 알 수 있습니다. Spy++에서 이 버튼 항목을 찾아 마우스 우측 클릭을 합니다. 그리고 컨텍스트 메뉴에서 'Messages'를 선택합니다. 그러면 Spy++는 운영체제에 들어오는 메시지를 몰래 훔쳐봅니다. 그리고 이 중에서 '더 보기/간단하게' 버튼에 통지되는 메시지를 모두 출력합니다. 아마 마우스를 버튼에 살짝 들이대는 순간부터 엄청나게 메시지가 쌓이는 것을 확인할 수 있을 것입니다. 하지만 여기서 다른 건 큰 의미가 없고, 중요한 것은 필요한 메시지는 마우스 클릭 관련 메시지입니다.
그럼 수많은 메시지 중 원하는 것만 선택해 보기로 합니다. 'Messages→Logging Options'를 선택합니다. 'Messages' 탭에서 체크된 메시지를 'Clear All' 버튼을 눌러 취소하고 'Mouse' 그룹의 메시지만 청취하도록 고칩니다. 단 'WM_SETCURSOR'와 'WM_MOUSEMOVE' 메시지를 선택하면 로그가 너무 많아지므로 이 둘은 선택 해제합니다. 'Messages→Clear Log'을 선택해 로그를 지운 후 다시 로그를 살펴봅니다. 이제는 그렇게 로그가 많이 쌓이지 않을 것입니다.
이제 버튼을 클릭해 보면 'WM_LBUTTONDOWN', 'WM_LBUTTONUP' 메시지가 확인될 겁니다. 이 두 메시지는 마우스 왼쪽 버튼을 각각 누르고 뗄 떼 발생하는 메시지입니다. 십중팔구 프로그램은 이 두 메시지에 대해 이벤트 핸들러를 만들어 두었을 것입니다.
스크립트로 발생시킨 이벤트로 타겟 프로그램을 동작시키기
이제 report_status.py 프로그램을 조금 더 수정하도록 합니다. 다음 함수를 report_status 클래스에 추가해 봅니다.
def toggle_listview(self): btnwnd = 0 for child in self.__childwnds: wnd_clas = win32gui.GetClassName(child) wnd_text = win32gui.GetWindowText(child) if wnd_clas == 'Button' and (wnd_text == '더 보기' or wnd_text == '간단하게'): btnwnd = child break win32gui.SendMessage(btnwnd, win32con.WM_LBUTTONDOWN, 0x01, 0xF0035) win32gui.SendMessage(btnwnd, win32con.WM_LBUTTONUP, 0x00, 0xF0035)
win32gui.SendMessage()의 3, 4번째 인자는 각각 wParam, lParam 이라고 하여 메시지 코드에 부가적으로 전달되는 데이터들입니다. 이 또한 Spy++에서 확인할 수 있습니다. 메시지 한 항목을 선택하고 “Properties…”를 클릭하면 확인 가능합니다. 0xF0035는 단순하게 마우스가 클릭한 좌표일 뿐이므로 크게 신경쓰지 않아도 됩니다. toggle_listview()를 실행하면 신기하게도 TeraCopy의 더 보기/간단하게 버튼을 클릭한 것처럼 파일 목록이 보였다 사라졌다 합니다. 이제 준비는 거의 끝났습니다.
웹서버와 통합하기
웹서버는 클라이언트가 접속할 때까지 대기하다가, 클라이언트가 접속을 하면 간단한 인증을 통해 페이지에 접근할 권한이 있는지를 확인합니다. 확인이 되면, report_status를 실행시켜 'status.html'을 새로 생성합니다. 그리고 생성된 status.html 파일을 클라이언트로 보냅니다.
그리고 우리는 타겟 프로그램을 웹페이지에서 조작하기를 원합니다. 웹페이지에도 더 보기/간단하게 버튼을 만들어서 웹브라우저에서 입력한 메시지를 타겟 프로그램까지 전달할 것입니다.
클라이언트에서 서버로 데이터를 전송하기 위해 HTML 코드에 폼(Form) 요소를 추가할 것입니다. report_status.py 코드에 살짝 추가하도록 하지요
- report_status_form.py
# -*- coding:cp949 -*- # TeraCopy 내부의 모든 윈도우 객체를 나열합니다. import win32gui import win32con import commctrl import pywintypes import struct, array import sys from ListViewItems import GetListViewItems # 부모 윈도우의 핸들을 검사합니다. class WindowFinder: def __init__(self, windowname): try: win32gui.EnumWindows(self.__EnumWindowsHandler, windowname) except pywintypes.error as e: # 발생된 예외 중 e[0]가 0이면 callback이 멈춘 정상 케이스 if e[0] == 0: pass def __EnumWindowsHandler(self, hwnd, extra): wintext = win32gui.GetWindowText(hwnd) if wintext.find(extra) != -1: self.__hwnd = hwnd return pywintypes.FALSE # FALSE는 예외를 발생시킵니다. def GetHwnd(self): return self.__hwnd __hwnd = 0 # 자식 윈도우의 핸들 리스트를 검사합니다. class ChildWindowFinder: def __init__(self, parentwnd): try: win32gui.EnumChildWindows(parentwnd, self.__EnumChildWindowsHandler, None) except pywintypes.error as e: if e[0] == 0: pass def __EnumChildWindowsHandler(self, hwnd, extra): self.__childwnds.append(hwnd) def GetChildrenList(self): return self.__childwnds __childwnds = [] # teracopy의 보고 기능 class teracopy_reporter: def __init__(self, windowname): self.__GetChildWindows(windowname) # windowname을 가진 윈도우의 모든 자식 윈도우 리스트를 얻어낸다. def __GetChildWindows(self, windowname): # TeraCopy의 window handle을 검사한다. self.__hwnd = WindowFinder(windowname).GetHwnd() # Teracopy의 모든 child window handle을 검색한다. self.__childwnds = ChildWindowFinder(self.__hwnd).GetChildrenList() # 리스트 뷰 컨트롤의 텍스트를 파일로 저장합니다. def report_status(self, save_as): listviewCtrl = 0 for child in self.__childwnds: wnd_clas = win32gui.GetClassName(child) if wnd_clas == 'SysListView32': listviewCtrl = child break item_grid = [] for i in range(5): column = GetListViewItems(listviewCtrl, i) item_grid.append(column) # html로 쓰기 html = '' with open(save_as, 'w') as f: html += "<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd\">\n" html += "<html>\n\t<head>\n\t\t<meta http-equiv=\"content-type\" content=\"text/html; charset=euc-kr\" />\n" html += "\t\t<title>TeraCopy Status</title>\n\t</head>\n" html += "<body>\n" # 폼 요소가 추가되었습니다. ######################################################## html += "\t<div style=\"margin:10px 0px;\">\n" html += "\t\t<form name=\"ActionForm\" method=\"GET\" action=\"status.html\">\n" html += "\t\t\t\n<input type=\"hidden\" name=\"togglelist\" value=\"1\" />\n" html += "\t\t\t<input type=\"submit\" value=\"전송\" />\n" html += "\t\t</form>\n" html += "\t</div>\n" ################################################################################# html += "\t<table border=\"1\">\n" html += "\t\t<tr>\n" html += "\t\t\t<th>원본파일</th>\n" html += "\t\t\t<th>크기</th>\n" html += "\t\t\t<th>상태</th>\n" html += "\t\t\t<th>원본 CRC</th>\n" html += "\t\t\t<th>대상 CRC</th>\n" html += "\t\t</tr>\n" for r in range(len(item_grid[0])): html += "\t\t<tr>\n" html += "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" \ "\t\t\t<td>%s</td>\n" % \ (item_grid[0][r], item_grid[1][r], item_grid[2][r], item_grid[3][r], item_grid[4][r]) html += "\t\t</tr>\n" html += "\t</table>\n" html += "</body>\n</html>\n" f.write(html) def toggle_listview(self): btnwnd = 0 for child in self.__childwnds: wnd_clas = win32gui.GetClassName(child) wnd_text = win32gui.GetWindowText(child) if wnd_clas == 'Button' and (wnd_text == '더 보기' or wnd_text == '간단하게'): btnwnd = child break win32gui.SendMessage(btnwnd, win32con.WM_LBUTTONDOWN, 0x01, 0xF0035) win32gui.SendMessage(btnwnd, win32con.WM_LBUTTONUP, 0x00, 0xF0035) __hwnd = 0 __childwnds = 0 if __name__ == '__main__': tr = teracopy_reporter('TeraCopy') tr.toggle_listview()
클라이언트에서 데이터를 보낼 준비가 끝났으니, 서버 또한 클라이언트가 보낸 데이터를 받을 준비를 해야 합니다.
- MonitorServer_03.py
# -*- coding:cp949 -*- from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler import urlparse, base64 import sys from report_status import teracopy_reporter class MyRequestHandler(BaseHTTPRequestHandler): def do_GET(self): try: addr, port = self.client_address print "Connection from", addr, "port", port print "Request header:" print self.headers urlparsed = urlparse.urlparse(self.path) urlpath = urlparsed.path query = urlparse.parse_qs(urlparsed.query) # print urlparsed # print urlpath # print query if urlpath == '/status.html': if self.login_process() == True: self.response200(query) else: self.response401() self.wfile.write('<P>Login Canceled.</P>') else: raise IOError() except IOError: self.send_error(404, 'File not found: %s' % self.path) def log_message(self, format, *args): pass # 로그 메시지 끄고 조용히 하기 위함 def login_process(self): if self.headers.has_key('Authorization'): authm, val = self.headers['Authorization'].split() userid, passwd = base64.b64decode(val).split(':') # print userid, passwd if userid == 'guest' and passwd == 'guestpass': return True return False # 응답 코드 200 def response200(self, query): self.send_response(200) self.send_header('Connection', 'Closed') self.send_header('Content-Type', 'text/html') self.end_headers() # TeraCopy의 정보를 HTML로 출력 tr = teracopy_reporter('TeraCopy') # togglelist라는 변수를 받을 경우 listview를 열고 닫는다. print query if query.has_key('togglelist'): tr.toggle_listview() # HTML 문서를 새롭게 만들도록 지시한다. tr.report_status('report_status.html') # 만들어진 문서를 읽어서 클라이언트로 보낸다. f = file('report_status.html', 'r') self.wfile.write(f.read()) f.close() # 응답 코드 401 (인증 필요) def response401(self): self.send_response(401) self.send_header('WWW-Authenticate', 'Basic realm=\"pyrealm\"') self.send_header('Content-Type', 'text/html') self.send_header('Connection', 'Closed') self.end_headers() # 상태 보고 서버를 시작함 def StartStatusServer(port): httpd = HTTPServer(('', port), MyRequestHandler) try: print "Status server started." httpd.serve_forever() except KeyboardInterrupt: print "Status server finished." def main(argv) : if len(argv) != 2: print >> sys.stderr, "Usage: MonitorServer_03.py <port number>" return 1 port = int(argv[1]) StartStatusServer(port) return 0 if __name__ == '__main__' : sys.exit(main(sys.argv))
웹페이지를 통해 TeraCopy의 진행 상황이 보고됩니다. 버튼을 누르면 파일 목록이 나타났다 사라졌다 합니다. 완성입니다!
마치며
파이썬으로 아주 간단한 웹서버를 구현해 보았습니다. 이 웹서버는 이전 문서를 응용하여 서버의 어떤 프로그램을 모니터링합니다. 사용자는 간단하지만 인증을 해야 접근할 수 있도록 해보기도 하였습니다.
또한 웹서버는 클라이언트로부터 메시지를 전송받습니다. 웹서버는 간단한 문자열 작업을 통해 이 메시지를 해석하며, 특정 메시지는 모니터링한 프로그램을 조작할 수도 있습니다.
여러 모듈이 뭉치니까 분량이 상당해졌네요. 그래도 파이썬이니까 이만큼 간결하게 되었다고 생각합니다. 질문이 있으시면 제 이메일(cs.chwnam@gmail.com)로 보내주세요. 그럼 이만 문서를 마칩니다.